핀터레스트(Pinterest), 광고 참여 모델 통합으로 효율성과 성능을 동시에 잡다
핀터레스트(Pinterest)는 홈 피드, 검색, 관련 핀 등 여러 표면에 광고를 노출하며, 각 표면마다 독립적인 광고 참여 모델을 운영했음
모델 통합을 통해 반복적인 작업(Duplicated Work) 감소, 훈련 비용(Training Cost) 절감, 유지보수 부담(Maintenance Burden) 완화를 달성
MMoE(Multi-gate-Mixture-of-Experts) 및 긴 사용자 시퀀스(Long User Sequences) 통합으로 온라인 지표(Online Metrics) 개선을 확인
표면별 보정(Surface-specific Calibration) 및 멀티태스크 학습(Multi-task Learning)을 통해 표면별 특성(Surface-specific Features) 반영 및 확장성 확보
DCNv2(DCNv2)를 활용한 프로젝션 레이어(Projection Layer), 요청 레벨 브로드캐스팅(Request-level Broadcasting)으로 인프라 비용(Infrastructure Cost) 절감
모델 통합의 배경: 분산된 광고 참여 모델의 문제점
핀터레스트(Pinterest)는 홈 피드, 검색, 관련 핀 등 여러 표면에 광고를 노출하며, 각 표면마다 독립적인 광고 참여 모델을 운영했다. 모델 파편화(Model Fragmentation)로 인해, 플랫폼 전체의 개선 사항을 적용하려면 여러 코드 경로에서 작업을 반복해야 했고, 하이퍼파라미터(Hyperparameter) 튜닝(Tuning) 또한 어려웠다. 또한, 유사한 아이디어를 각 모델별로 검증해야 하므로 훈련 오버헤드(Training Overhead)가 증가하고, 3개의 시스템을 운영, 디버깅, 진화시키는 데 많은 유지보수 비용이 발생했다. 이러한 문제점을 해결하기 위해 모델 통합을 시작했다.
단일 모델 아키텍처 설계: 점진적 통합 전략
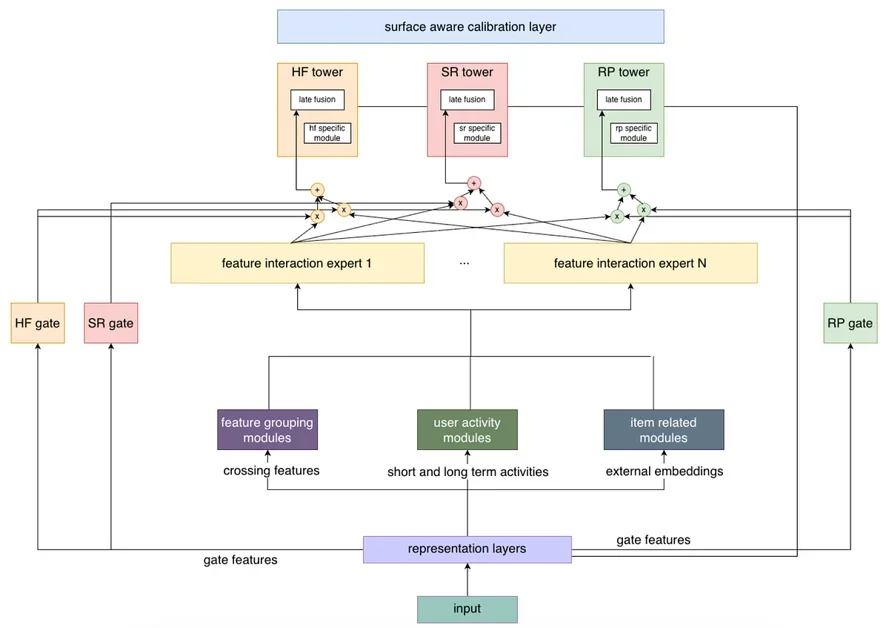
핀터레스트(Pinterest)는 모델 통합을 주요 아키텍처 변경으로 간주하고, 세 가지 원칙을 따랐다. 첫째, 가장 강력한 기존 구성 요소(Strongest Existing Components)를 병합하여 실용적인 기준선을 설정했다. 둘째, 기준선에서 가치를 입증한 후에 표면 인식 모델링(Surface-aware Modeling)을 점진적으로 도입했다. 셋째, 모든 단계에서 안전한 롤아웃(Rollout), 모니터링(Monitoring), 빠른 롤백(Rollback)을 위한 설계를 유지했다. 특히, 홈 피드(Home Feed)와 검색(Search) 모델을 먼저 통합하고, 이후 관련 핀(Related Pins) 모델을 통합하는 방식으로 진행했다.
성능 개선을 위한 아키텍처 개선: MMoE 및 긴 시퀀스 통합
홈 피드(Home Feed)와 검색(Search) 모델 통합 과정에서 MMoE(Multi-gate-Mixture-of-Experts) 및 긴 사용자 시퀀스(Long User Sequences)와 같은 핵심 아키텍처 요소를 통합했다. 개별적으로 적용했을 때는 일관된 성능 향상을 얻지 못했지만, 통합 모델에 적용하고, 결합된 특징(Combined Features)과 다중 표면 훈련 데이터(Multi-surface Training Data)를 활용하여 강력한 성능 개선(Stronger Improvements)을 달성했다. 최종 아키텍처는 표면별 타워 트리(Tower Trees)와 표면별 모듈을 지원하며, 각 표면의 트래픽(Traffic)만 처리하여 불필요한 컴퓨팅 비용을 줄였다.
효율성 향상을 위한 최적화: 프로젝션 레이어 및 브로드캐스팅
모델 통합은 인프라 비용 절감으로 자동 연결되지 않으므로, 핀터레스트(Pinterest)는 효율성 향상을 위한 노력을 병행했다. DCNv2(DCNv2)를 사용하여 트랜스포머(Transformer) 출력값을 작은 표현으로 투영(Projection)하여, 다운스트림 교차 및 타워 트리 레이어의 계산 경로를 단순화했다. 또한, 융합된 커널 임베딩(Fused Kernel Embedding)을 활성화하여 추론 지연 시간(Inference Latency)을 개선하고, TF32를 사용하여 훈련 속도(Training Speed)를 높였다. 요청 레벨 브로드캐스팅(Request-level Broadcasting)을 통해 중복된 임베딩 테이블(Embedding Table) 조회 작업을 줄여, 모델 입력 및 출력을 변경하지 않고, 배치(Batch)당 고유 사용자 수에 대한 상한을 설정했다.
온라인 및 오프라인 지표 개선: 검증된 성능 향상
오프라인 실험(Offline Experiments)에서 홈 피드(Home Feed)와 검색(Search) 모두에서 개선을 확인했으며, 온라인 실험(Online Experiments)을 통해 성능 향상을 검증했다. 표면별 보정(Surface-specific Calibration)을 통해 CTR(Click-Through Rate) 예측 성능을 향상시켰다. 또한, 멀티태스크 학습(Multi-task Learning) 설계를 통해 표면별 특징(Surface-specific Features)을 더욱 유연하게 예측하고, 표면별 체크포인트(Checkpoint)를 내보내 표면별 반복(Surface-specific Iteration)을 위한 기반을 마련했다. 이러한 개선 사항들을 통해 핀터레스트(Pinterest)는 광고 참여 모델의 효율성과 성능을 모두 향상시켰다.