넷플릭스(Netflix) 추천 시스템, JDK Vector API로 CPU 사용량 10% 절감!
넷플릭스(Netflix)의 추천 시스템인 Ranker에서 비디오 유사성 점수 계산(Video Serendipity Scoring)이 CPU 사용량의 7.5%를 차지하며 병목 현상 발생
배칭(Batching), 메모리 레이아웃 재설계, BLAS(BLAS) 라이브러리 시도 등 다양한 최적화 시도 끝에 JDK Vector API(JDK Vector API) 도입
JDK Vector API를 통해 CPU 사용률을 약 10% 감소시키고, 평균 지연 시간(Latency)을 12% 줄여 전반적인 시스템 성능 향상(Overall System Performance Improvement)을 달성
추천 시스템 성능 병목 지점 분석
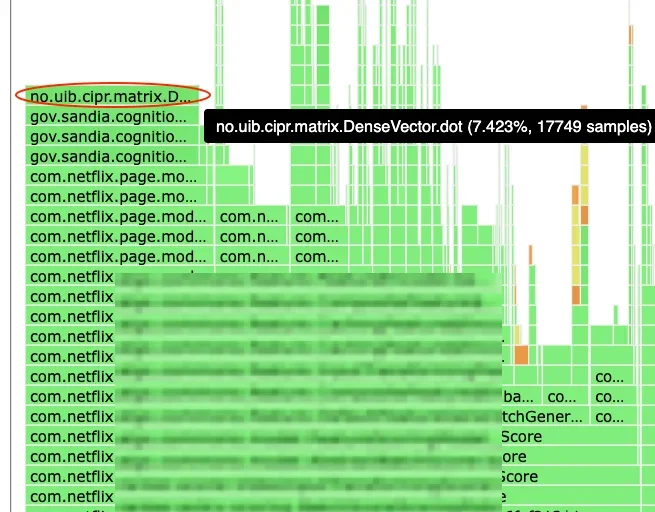
본문에서는 넷플릭스(Netflix) Ranker 서비스의 비디오 유사성 점수 계산(Video Serendipity Scoring)이 CPU 사용량의 주요 병목 지점임을 밝힌다. 기존 구현은 각 후보 비디오와 시청 기록 간의 코사인 유사도를 개별적으로 계산하는 O(M×N)의 계산 복잡도(Computational Complexity)를 가졌다. 이로 인해 반복적인 임베딩(Embedding) 조회, 메모리 흩어짐(Scattered Memory Access), 캐시 지역성(Cache Locality) 저하 등의 문제가 발생했다. 특히, 98%의 요청이 단일 비디오에 대한 것이었지만, 나머지 2%의 대량 배치 요청이 전체 CPU 사용량에 큰 영향을 미쳤다.
배칭(Batching) 기법을 활용한 행렬 연산 최적화
저자는 O(M×N)의 개별 연산을 행렬 곱셈(Matrix Multiplication)으로 변환하여 성능을 개선했다. 후보 비디오와 시청 기록의 임베딩을 각각 M x D, N x D 형태의 행렬로 구성하고, 코사인 유사도를 계산하기 위해 C = A x B^T 연산을 수행했다. 또한, ThreadLocal 기반의 버퍼 홀더(Buffer Holder)를 도입하여 각 스레드(Thread)가 재사용 가능한 버퍼를 소유하도록 설계했다. 이로 인해 요청당 메모리 할당을 줄이고, GC(Garbage Collection) 압력을 감소시켜 캐시 효율성(Cache Efficiency)을 향상시켰다.
BLAS(BLAS) 라이브러리 도입의 한계
BLAS(Basic Linear Algebra Subprograms) 라이브러리를 활용하여 행렬 연산을 가속화하려 했으나, 실제 프로덕션 환경에서 기대한 성능 향상을 얻지 못했다. Netlib-java의 F2J(Fortran-to-Java) BLAS 사용으로 인한 성능 저하, JNI(Java Native Interface) 호출 오버헤드, Java의 행 우선(Row-major) 메모리 레이아웃과 BLAS 루틴의 열 우선(Column-major) 요구사항 간의 불일치로 인한 데이터 변환(Data Conversion) 등이 문제점으로 지적되었다. 이러한 이유로 BLAS는 유용한 실험이었지만, 실제 적용에는 어려움이 있었다.
JDK Vector API를 활용한 SIMD(SIMD) 최적화
JDK Vector API는 Java 코드 내에서 데이터 병렬 연산을 표현할 수 있는 기술로, SIMD(Single Instruction, Multiple Data) 명령어를 활용하여 성능을 향상시킨다. 저자는 JDK Vector API를 통해 순수 Java 기반의 SIMD 구현을 선택하여 JNI 오버헤드(Overhead)를 제거하고, flat buffer 아키텍처(Architecture)를 유지했다. DoubleVector.SPECIES_PREFERRED를 사용하여 런타임(Runtime)에 적합한 레인(Lane) 폭을 선택하고, fma() (fused multiply-add) 연산을 통해 dot product를 계산했다. 이로 인해 기존의 loop-unrolled scalar dot product를 벡터화된 행렬 곱셈(Vectorized Matrix Multiplication)으로 대체하여 CPU 사용률을 크게 줄였다.
안정적인 운영을 위한 폴백(Fallback) 전략
JDK Vector API는 아직 Incubating 상태이므로, API 미지원 환경에 대한 폴백(Fallback) 전략을 마련했다. 서비스 시작 시 Vector API 지원 여부를 감지하고, 지원 시 SIMD 기반의 행렬 곱셈을 사용하고, 미지원 시 최적화된 스칼라(Scalar) 연산을 사용하도록 설계했다. 이를 통해 Vector API 사용 여부에 관계없이 안정적인 서비스 운영을 보장하며, 성능과 안정성(Stability)을 모두 확보했다. 결과적으로 CPU 사용률 약 10% 감소, 평균 지연 시간(Latency) 12% 감소, 그리고 function operator 레벨에서 CPU 사용률이 7.5%에서 1%로 감소하는 효과를 얻었다.