넷플릭스(Netflix), JDK Vector API로 추천 시스템(Recommendation System) 성능 10% 향상!
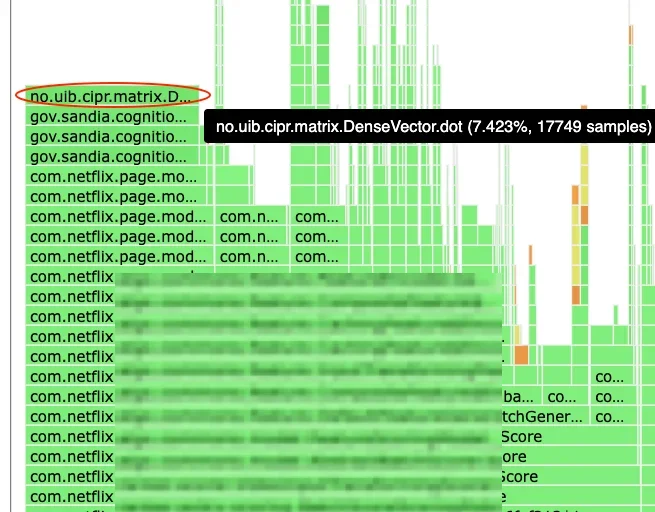
넷플릭스(Netflix)의 추천 시스템(Recommendation System)에서 비디오 유사성 점수 계산(Video Serendipity Scoring)이 CPU 사용량의 7.5%를 차지하는 병목 지점(Bottleneck)으로 확인됨
배칭(Batching), 플랫 버퍼(Flat Buffers), ThreadLocal 재사용(ThreadLocal Reuse) 등 메모리 레이아웃(Memory Layout) 최적화를 통해 성능 개선 시도
JDK Vector API를 활용한 SIMD(Single Instruction, Multiple Data) 구현을 통해 CPU 사용량 7% 감소 및 평균 지연 시간 12% 감소 달성
커뮤니티에서는 JDK Vector API의 실용성과 성능에 대한 긍정적 평가와 함께 실제 서비스 적용 경험 공유에 대한 기대감을 보임
추천 시스템(Recommendation System) 성능 병목 지점 분석
넷플릭스(Netflix)는 추천 시스템(Recommendation System)의 비디오 유사성 점수 계산(Video Serendipity Scoring)에서 CPU 사용량 과다 문제를 겪었다. 초기 구현은 O(M×N)의 복잡도(Complexity)를 가진 중첩 루프 구조로, 각 비디오 쌍에 대한 개별적인 코사인 유사도 계산이 병목 현상을 유발했다. CPU 프로파일링(CPU Profiling)을 통해 이 문제를 확인하고, 성능 개선을 위한 다양한 시도를 시작했다.
배칭(Batching) 및 메모리 레이아웃(Memory Layout) 최적화
초기에는 배칭(Batching)을 통해 M×N개의 개별적인 점 곱 연산을 단일 행렬 곱셈으로 대체하여 성능 향상을 시도했다. 하지만, double[][] 형태의 메모리 할당(Memory Allocation)과 비연속적인 메모리 접근으로 인해 GC(Garbage Collection) 부하가 증가하고 캐시 효율성이 저하되는 문제가 발생했다. 이후 플랫 버퍼(Flat Buffers)와 ThreadLocal 재사용(ThreadLocal Reuse)을 도입하여 메모리 할당 비용을 줄이고 캐시 효율성을 개선했다.
JDK Vector API를 활용한 SIMD(Single Instruction, Multiple Data) 구현
BLAS(Basic Linear Algebra Subprograms) 라이브러리 사용 시 JNI(Java Native Interface) 오버헤드와 Java의 행 우선 메모리 레이아웃과의 불일치로 인한 성능 저하가 발생했다. 대안으로 JDK Vector API를 활용하여 순수 Java 기반의 SIMD 구현을 시도했다. SIMD(Single Instruction, Multiple Data)를 통해 여러 개의 데이터를 동시에 처리하여 CPU 성능을 극대화하고, JNI 의존성 문제를 해결했다.
실제 서비스 적용 결과 및 성능 개선 효과
최적화된 시스템은 CPU 사용량 7% 감소, 평균 지연 시간 12% 감소라는 긍정적인 결과를 얻었다. 특히, CPU/RPS(Request Per Second) 지표가 약 10% 개선되어 동일한 트래픽을 처리하는 데 필요한 CPU 자원을 줄였다. 또한, JDK Vector API의 안전한 폴백(Fallback) 메커니즘을 통해 API 미지원 환경에서도 안정적인 서비스 운영을 보장했다. 어셈블리 레벨(Assembly Level)에서 SIMD 명령어를 활용하는 것을 확인했다.