EKS에서 Slinky로 Slurm 통합 관리 시작!
by DD
5개월 전
조회수 42
AI 인프라 구축 시 Slurm과 Kubernetes를 별도 클러스터로 관리하는 운영 오버헤드 및 리소스 활용률 저하 문제 발생
오픈 소스 Slinky Project를 통해 Amazon EKS 환경에서 Slurm을 실행하여 두 플랫폼의 장점 통합
통합 컴퓨팅 환경 구성으로 운영 효율성 증대 및 보유 리소스 가용성 최대화
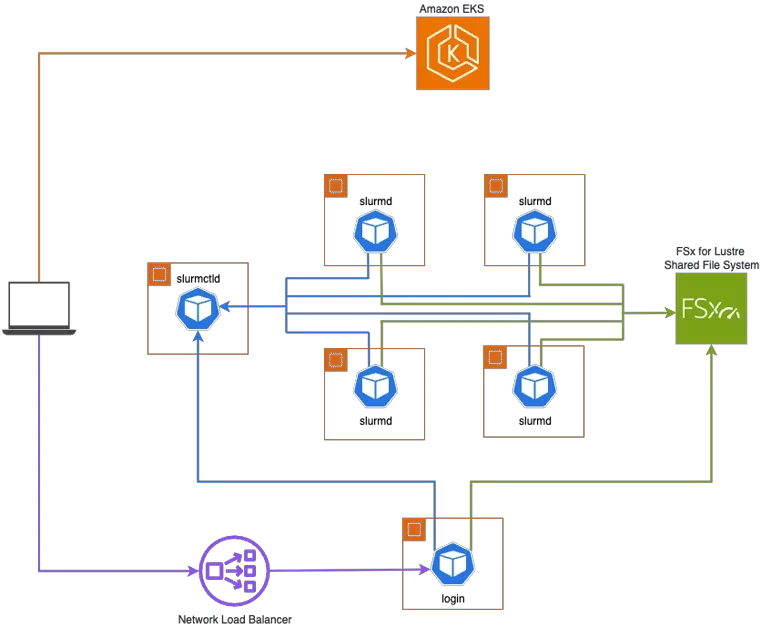
Slinky를 통한 Slurm과 Kubernetes의 통합 아키텍처
Slinky는 Slurm 워크로드 매니저를 Kubernetes 네이티브 방식으로 통합하는 오픈 소스 프로젝트임. 기존의 분리된 Slurm 클러스터와 Kubernetes 클러스터를 Amazon EKS와 같은 단일 Kubernetes 환경에서 공존시킴으로써, 운영 복잡성을 줄이고 리소스 활용률을 극대화하는 것을 목표로 함.
핵심 구성 요소는 다음과 같음:
컨트롤러 파드(Controller Pod): slurmctld 데몬을 실행하여 리소스 관리 및 작업 할당 담당.
어카운팅 파드(Accounting Pod): slurmdbd 데몬과 MariaDB를 연동하여 작업 사용량 기록 관리.
REST API 파드(REST API Pod): slurmrestd 데몬을 통해 HTTP 기반 API 제공 및 NodeSet 컨트롤러와 연동.
워커 노드 파드(Worker Node Pod): slurmd 데몬을 실행하며, 사용자가 지정한 노드 셀렉터 및 리소스 쿼터에 따라 EC2 가속화 인스턴스에서 실행됨.
로그인 파드(Login Pod): 사용자가 Slurm 명령어를 실행하고 작업을 제출할 수 있는 환경 제공.
이 아키텍처는 데이터 격리 아키텍처(Data Isolation Architecture)를 통해 Slurm 작업과 Kubernetes 네이티브 워크로드가 동일한 인프라를 공유하면서도 서로의 리소스에 영향을 주지 않도록 설계됨.
Slurm Operator의 동적 오토스케일링 및 비용 효율성
Slinky의 Slurm Operator는 워크로드 수요 변화에 따라 워커 노드 파드를 동적으로 프로비저닝하고 종료하는 기능을 제공함. 이는 클라우드 컴퓨팅 리소스의 비용 효율성을 크게 향상시킴.
주요 특징은 다음과 같음:
실시간 워크로드와 배치 워크로드의 공존: AI 추론과 같은 실시간 워크로드는 트래픽 증가에 따라 신속하게 스케일 아웃하고, AI 학습과 같은 배치 워크로드는 작업 큐 기반으로 업무 외 시간에 스케일 아웃 가능.
Karpenter 또는 Cluster Autoscaler 연동: 온디맨드 EC2 인스턴스 활용을 최적화하며, On-Demand Capacity Reservations (ODCRs) 또는 Capacity Blocks for ML 사용 지원.
Scale-to-Zero 지원: Horizontal Pod Autoscaler (HPA)와 연동하여 워커 노드 파드를 0개 복제본으로 축소 가능.
이를 통해 조직은 유휴 리소스 낭비를 최소화하고, 실제 사용량에 기반한 비용 최적화를 달성할 수 있음.
Slinky 도입 시 고려사항 및 대안 비교
Slinky는 Slurm과 Kubernetes의 통합을 통해 이기종 워크로드 관리를 간소화하지만, 도입 시 몇 가지 고려사항이 존재함. 특히 기존 Slurm 환경과의 호환성 및 마이그레이션 복잡성을 평가해야 함.
주요 대안은 다음과 같음:
AWS ParallelCluster: 자체 관리형 Slurm 클러스터 설정을 자동화하며, 높은 수준의 제어와 커스터마이징을 제공. IaC(Infrastructure as Code) 지원.
AWS Parallel Computing Service (AWS PCS): 보다 완전 관리형 Slurm 환경을 제공하며, 컨트롤러 패치 자동 업데이트, 관리형 어카운팅 등 운영 부담 감소.
Amazon SageMaker HyperPod: 대규모 분산 ML 워크로드 자동화 및 최적화에 특화. 영구적이고 자가 복구 가능한 클러스터 제공.
Kubernetes 네이티브 스케줄러 (Volcano, Apache YuniKorn, Kueue): Kubernetes 환경에 직접 통합되어 배치 작업, 멀티 테넌시, 공정한 리소스 공유 등에 강점을 가짐.
Slinky는 실시간 워크로드와 배치 워크로드를 모두 관리해야 하는 조직에 적합하며, 특히 Kubernetes 환경을 표준화하려는 경우 유용함.
Slurm 클러스터의 구성 요소 및 기능 상세
Slinky는 컨테이너화된 Slurm 클러스터를 통해 기존 Slurm의 핵심 기능을 Kubernetes 환경에서 제공함. 각 구성 요소는 특정 역할을 수행하며 상호 연동됨.
주요 구성 요소 및 기능:
slurmctld (컨트롤러 파드): 중앙 관리 데몬으로, 리소스 모니터링, 작업 수락, 노드 할당 담당.
slurmdbd (어카운팅 파드): MariaDB와 연동하여 작업 사용량 및 리소스 할당 기록 관리. 데이터 미저장 정책(Zero-Retention Policy)과는 무관하게 사용량 기록을 아카이빙함.
slurmrestd (REST API 파드): HTTP 기반 API를 제공하여 프로그래밍 방식 상호 작용 지원. NodeSet 컨트롤러 및 메트릭 익스포터와 연동.
slurmd (워커 노드 파드): 현재 실행 중인 작업 모니터링, 작업 시작 및 종료 처리. 사용자가 지정한 노드 셀렉터 및 리소스 쿼터에 따라 EC2 가속화 인스턴스에서 실행됨.
로그인 파드(Login Pod): 사용자가 Slurm 명령어를 실행하고 작업을 제출하는 작업 공간 제공. SSH 접근 및 LDAP 기반 인증 지원.
메트릭 익스포터: Prometheus 메트릭 포맷으로 텔레메트리 데이터 수집 및 내보내기. KEDA와 연동하여 사용자 지정 메트릭 기반 스케일링 지원.
이러한 구성 요소들은 Kubernetes Operator에 의해 관리되어 Slurm 클러스터의 수명 주기를 효과적으로 제어함.
AI 워크로드 관리를 위한 Slurm의 역할과 장점
Slurm은 전통적으로 HPC 환경에서 사용되어 왔으나, 대규모 AI 학습 및 추론 워크로드 관리에도 적합한 특성을 지님. Slinky는 이러한 Slurm의 강점을 Kubernetes 환경으로 확장함.
Slurm의 주요 장점:
뛰어난 확장성: 다양한 규모의 컴퓨팅 클러스터에서 리소스 관리 및 작업 스케줄링 가능.
세밀한 리소스 제어: 연구자 및 엔지니어가 CPU, GPU, 메모리 등 리소스 유형과 작업 우선순위를 정밀하게 제어 가능.
결정론적 스케줄링: 장시간 실행되는 배치 작업의 안정적인 실행 보장.
고급 스케줄링 기능: 작업 큐 관리, 리소스 경합 해소 등 복잡한 스케줄링 요구사항 충족.
재현성(Reproducibility) 확보: 동일한 환경에서 작업을 반복 실행하여 결과의 재현성을 높임.
Slinky를 통해 Kubernetes 환경에서 Slurm을 사용하면, AI 모델 학습 및 추론 파이프라인의 효율성을 높이고 재현 가능한 연구 환경을 구축하는 데 기여함.