EKS Auto Mode로 AI 플랫폼 운영 자동화 & 비용 절감!
by DD
2개월 전
조회수 10
LLM 기반 에이전트(Agent)의 확장성 한계를 극복하기 위해, 고성능 LLM과 도메인 특화 SLM을 결합한 이질적 다중 모델(Heterogeneous Multi-model) 생태계 구축
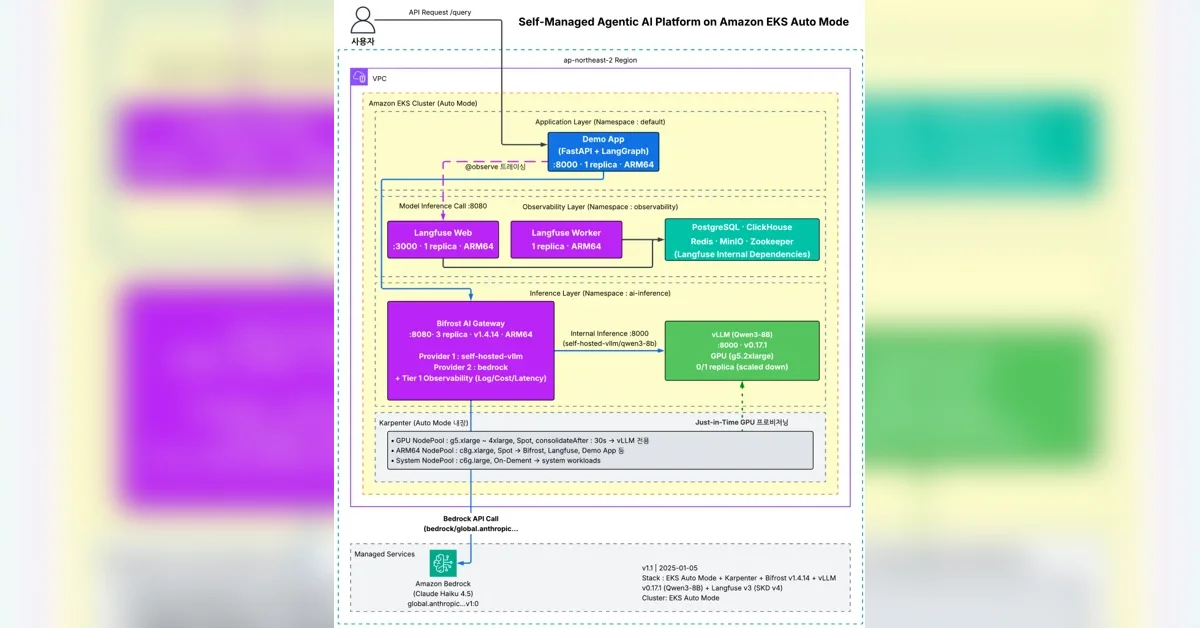
Amazon EKS Auto Mode를 활용하여 GPU 인프라를 자동화하고, Bifrost AI Gateway로 자체 호스팅 모델과 Amazon Bedrock을 통합
2-Tier 관측성(Observability) 확보를 위해 Bifrost(인프라 레벨)와 Langfuse(애플리케이션 레벨)를 활용하여 비용 최적화(Cost Optimization)와 품질 관리
EKS Auto Mode는 Karpenter를 통해 GPU 노드 자동 프로비저닝(GPU Node Auto-provisioning) 및 Spot 인스턴스 활용을 지원하여 비용 절감
자체 호스팅 vLLM과 Bedrock의 멀티 모델 라우팅(Multi-model Routing)을 통해 쿼리 유형에 따라 최적의 모델을 선택, API 비용 75% 절감
EKS Auto Mode를 활용한 GPU 인프라 자동화
본문은 Amazon EKS Auto Mode를 통해 GPU 인프라 프로비저닝(Provisioning)과 관리를 자동화하는 방법을 제시한다. EKS Auto Mode는 Karpenter(Karpenter)를 내장하여 GPU 노드의 Just-in-Time 프로비저닝(Just-in-Time Provisioning)과 Spot 인스턴스(Spot Instance) 활용을 자동 처리한다.
자동화된 컴포넌트 관리: VPC CNI, EBS CSI Driver, CoreDNS 등 핵심 컴포넌트 자동 설치 및 업그레이드