EKS에서 NVIDIA OSMO로 Physical AI 워크플로를 효율적으로 운영하는 방법
by DD
1개월 전
조회수 4
Physical AI 워크플로의 복잡한 라이프사이클 관리를 위해 Amazon EKS 기반의 레퍼런스 아키텍처를 제시함
NVIDIA OSMO를 중심으로 Karpenter, GPU Operator, AWS 관리형 서비스 등을 통합하여 GPU 워크로드 운영 효율성을 높임
반복 가능한 운영 패턴을 통해 GPU 스케줄링, 아티팩트 보존, 관찰 가능성, 보안을 통합 관리함
순차 및 병렬 실행 패턴을 활용하여 데이터 생성부터 모델 학습까지의 파이프라인을 효과적으로 구성함
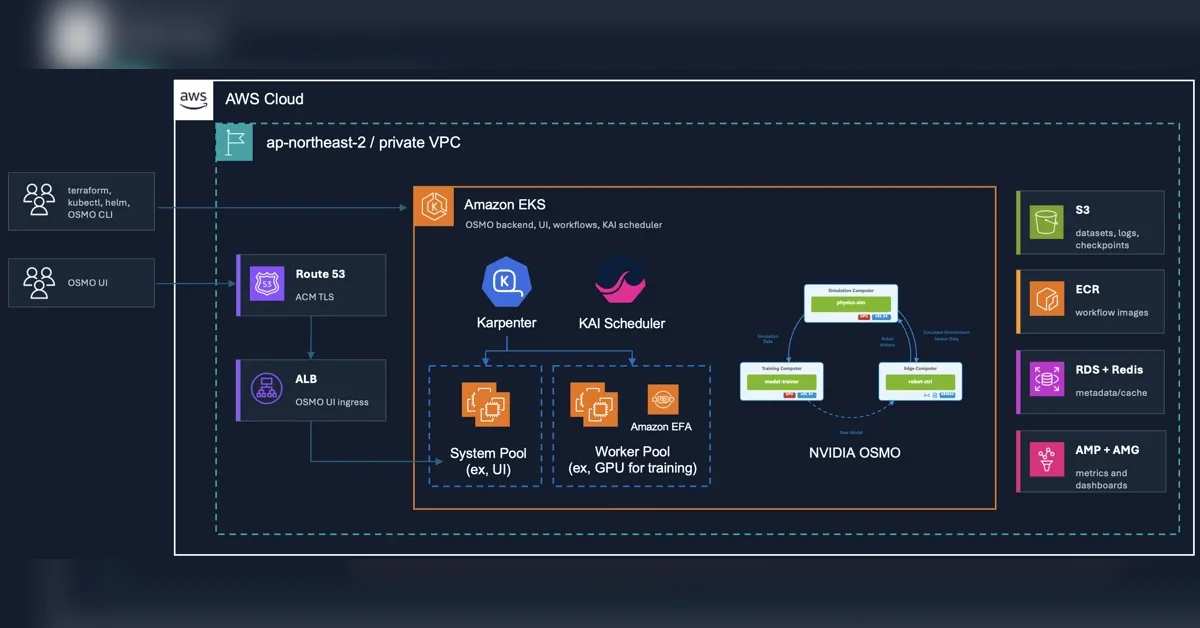
Amazon EKS 기반 Physical AI 워크플로 아키텍처
본 아키텍처는 Amazon EKS(Amazon Elastic Kubernetes Service)를 관리형 Kubernetes 컨트롤 플레인으로 활용하며, NVIDIA OSMO 워크플로 파드는 Karpenter 기반 EC2 GPU 인스턴스에서 실행됨. 데이터 저장소로는 Amazon S3 기반 아티팩트 저장소를 사용하고, 메타데이터 및 시크릿 관리는 AWS 관리형 백엔드 서비스(RDS, ElastiCache, Secrets Manager 등)를 통해 이루어짐. Amazon Managed Service for Prometheus(AMP)와 Amazon Managed Grafana(AMG)는 클러스터 및 GPU 메트릭 수집과 시각화를 담당하며, Elastic Fabric Adapter(EFA)는 분산 학습 시 네트워크 가속을 제공함. 이러한 구성은 GPU 스케줄링, 아티팩트 보존, 관찰 가능성, 보안을 통합된 운영 패턴으로 관리 가능하게 함.