결정 트리(Decision Tree)의 모든 것: 원리, 장점, 그리고 함정
결정 트리(Decision Tree)는 데이터의 특징(Features)을 기반으로 의사 결정 규칙을 생성하여 분류 및 회귀 문제에 활용되는 알고리즘임
엔트로피(Entropy) 및 정보 이득(Information Gain) 개념을 통해 최적의 분할 기준을 결정하며, 모델의 해석 용이성이 장점임
과적합(Overfitting) 문제와 데이터 변동에 대한 민감성(Sensitivity)은 결정 트리의 주요 단점으로 지적됨
실제 운영 환경에서 결측치(Missing Values) 처리의 중요성이 강조되며, 안정적인 모델 구축을 위한 추가적인 고려 사항 제시
결정 트리(Decision Tree)의 기본 원리
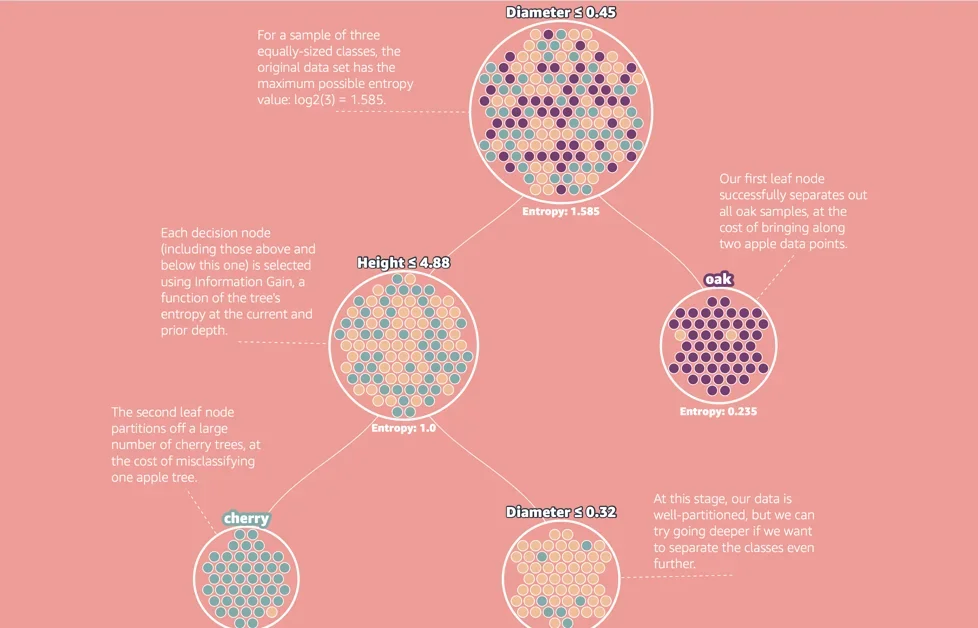
결정 트리는 데이터의 특징(Features)을 기반으로 데이터를 분할하여 분류 또는 회귀 문제를 해결하는 지도 학습(Supervised Learning) 알고리즘이다. 각 노드에서 특정 조건(예: 나무의 지름 ≤ 0.45)을 기준으로 데이터를 분할하며, 리프 노드(Leaf Node)에서 최종 예측값을 출력한다. 이러한 구조는 모델의 해석 가능성(Interpretability)을 높이는 장점으로 이어진다.
엔트로피(Entropy)와 정보 이득(Information Gain)의 역할
결정 트리 알고리즘은 엔트로피(Entropy) 개념을 활용하여 데이터의 불순도(Impurity)를 측정하고, 정보 이득(Information Gain)을 최대화하는 방향으로 분할을 수행한다. ID3 알고리즘은 각 특징(Feature)에 대한 엔트로피를 계산하고, 분할 후의 정보 이득을 비교하여 최적의 분할 기준을 선택한다. 이러한 과정을 통해 트리는 데이터의 패턴을 학습하고, 예측 정확도를 높인다.
결정 트리(Decision Tree)의 한계점: 과적합(Overfitting)과 민감성
결정 트리는 과적합(Overfitting) 문제에 취약하며, 훈련 데이터(Training Data)에 과도하게 맞춰져 새로운 데이터에 대한 일반화 성능이 저하될 수 있다. 또한, 훈련 데이터의 작은 변화에도 트리 구조가 크게 변동되는 민감성(Sensitivity)을 보인다. 이러한 단점을 보완하기 위해 트리 가지치기(Pruning) 또는 앙상블(Ensemble) 기법을 활용한다.
실제 운영 환경에서의 결측치(Missing Values) 문제
댓글에서는 실제 운영 환경에서 결측치(Missing Values) 처리의 중요성을 강조한다. 훈련 데이터에 없는 결측치가 발생하면 모델의 정확도가 급격히 저하될 수 있다. 따라서 결측치 처리 전략(예: 평균값 대체, 모델 재훈련)을 사전에 마련하고, 데이터 품질 관리(Data Quality Management)에 주의를 기울여야 한다.