결정 트리(Decision Tree)의 원리, 엔트로피와 정보 획득을 파헤치다!
by DD
2개월 전
조회수 10
결정 트리(Decision Tree)는 지도 학습(Supervised Learning) 알고리즘으로, 분류 및 회귀 문제에 널리 사용됨
엔트로피(Entropy)는 데이터의 불순도(Impurity)를 측정하는 지표로, 정보 획득(Information Gain) 계산에 활용됨
ID3 알고리즘은 엔트로피를 기반으로 정보 획득을 최대화하는 방식으로 결정 트리를 구축함
결정 트리는 해석이 용이하지만, 과적합(Overfitting) 문제에 취약하여 가지치기(Pruning) 등의 기법이 필요함
결정 트리(Decision Tree)의 기본 구조
결정 트리는 일련의 결정 노드(Decision Node)로 구성되며, 각 노드는 데이터의 특징(Feature)에 대한 조건을 나타낸다. 이러한 조건은 if-then 규칙(If-Then Rules)을 통해 구현되며, 각 노드는 두 개 이상의 하위 노드로 분기된다. 최종적으로, 리프 노드(Leaf Node)는 모델의 예측 결과를 나타낸다. 데이터는 루트 노드에서 시작하여 리프 노드에 도달할 때까지 트리를 따라 이동하며 분류 또는 회귀 예측을 수행한다.
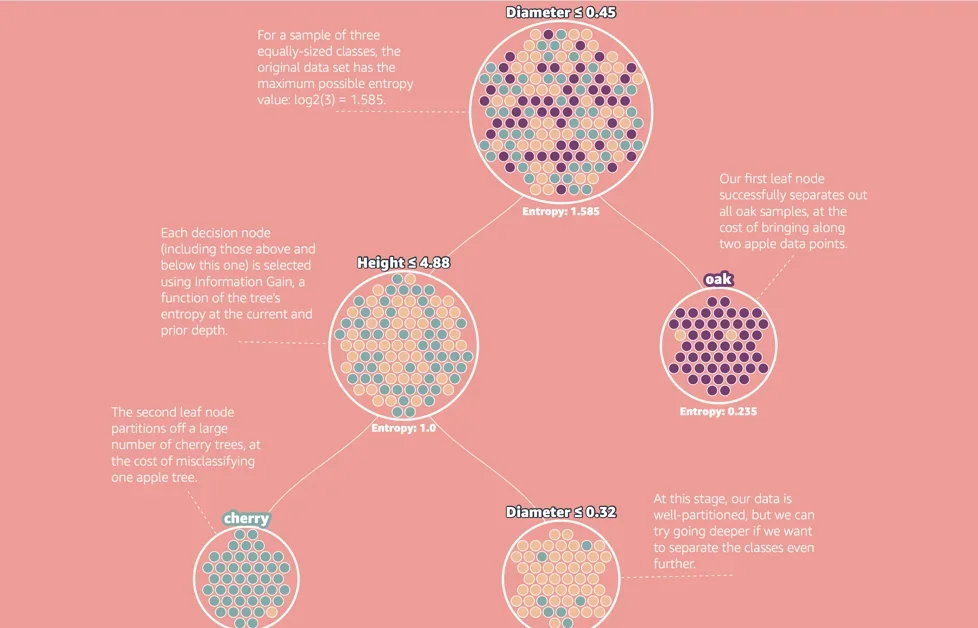
엔트로피(Entropy)와 정보 획득(Information Gain)
결정 트리의 핵심은 데이터를 분할하는 최적의 조건을 찾는 것이다. 이를 위해 엔트로피(Entropy) 개념이 사용되는데, 엔트로피는 데이터 집합의 불확실성 또는 불순도를 측정한다. 정보 획득(Information Gain)은 분할 전후의 엔트로피 차이를 계산하여, 분할으로 얻을 수 있는 정보의 양을 측정한다. ID3 알고리즘은 정보 획득을 최대화하는 분할을 선택하여 트리를 구축한다.
ID3 알고리즘의 작동 원리
ID3 알고리즘은 각 특징(Feature)에 대한 엔트로피를 계산하고, 다양한 분할 기준을 적용하여 정보 획득을 계산한다. 알고리즘은 정보 획득이 가장 큰 분할을 선택하고, 해당 특징과 분할 값을 결정 노드로 생성한다. 이 과정을 재귀적으로 반복하며, 리프 노드에 도달할 때까지 트리를 확장한다. 재귀는 더 이상 분할할 수 없거나, 특정 조건을 만족할 때 종료된다.
결정 트리의 한계와 개선 방안
결정 트리는 해석이 용이하고, 전처리(Preprocessing)가 간단하다는 장점이 있지만, 과적합(Overfitting)에 취약하다는 단점이 있다. 과적합은 훈련 데이터의 노이즈(Noise)에 과도하게 적합되어, 새로운 데이터에 대한 일반화 성능을 저하시킨다. 이를 해결하기 위해 가지치기(Pruning), 최대 깊이 제한, 리프 노드의 최소 샘플 수 설정 등 다양한 기법이 사용된다. 또한, 앙상블(Ensemble) 방법을 통해 단일 결정 트리의 불안정성을 보완할 수 있다.