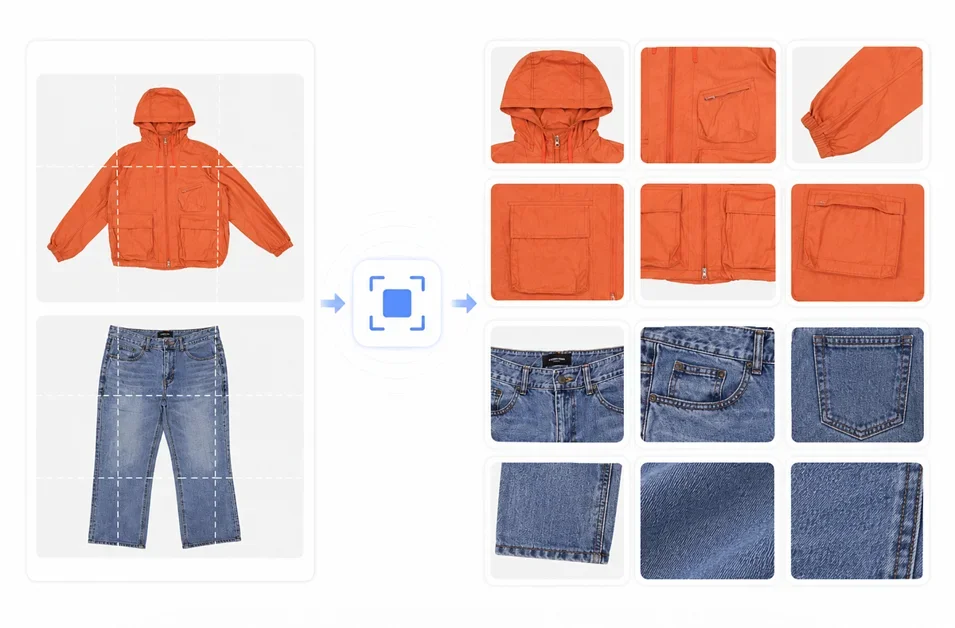
VLM 대신 Object Detector로 의류 디테일컷 자동화, 25배 빨라졌다!
by DD
1개월 전
조회수 62
무신사 유즈드는 AI 기반 의류 디테일컷 자동화 시스템 구축을 위해 VLM(Vision-Language Model) 대신 Object Detector를 선택
Object Detector와 Rule-based Crop 결합으로 VLM 대비 25배 빠른 추론 속도 달성 및 90% 공정 시간 절감 성공
의류의 공간적 규칙성(Geometric Prior)을 활용하여, VLM의 불필요한 추론 과정을 제거하고 문제 해결의 효율성(Efficiency)을 극대화
AWS Lambda를 서빙 인프라로 선택, 유휴 시간 비용 절감(Idle Time Cost Reduction) 및 팀의 기술 스택(Tech Stack)을 고려한 유연한 아키텍처 구성
VLM 대신 Object Detector를 선택한 이유
무신사 유즈드는 의류 디테일컷 자동화를 위해 VLM(Vision-Language Model)을 먼저 고려했으나, 추론 속도(Inference Speed)와 비용 효율성(Cost Efficiency) 문제로 Object Detector로 전환했다. VLM은 이미지 이해와 추론에 특화되어, “소매를 찾아서 크롭해줘”와 같은 자연어 기반 지시에 적합하다. 하지만, 의류 부위의 위치를 찾는 문제에는 VLM의 자연어 처리 오버헤드(Natural Language Processing Overhead)가 불필요했다. Object Detector는 이미지 내 객체의 위치를 수치로 정확히 추출하는 데 집중하며, CPU 환경에서 200ms 내외로 추론을 완료하여 VLM 대비 25배 빠른 속도를 달성했다.
Detector + Rule-based Crop 아키텍처 설계
본 시스템은 Object Detector로 의류의 위치를 파악하고, Rule-based Crop으로 부위별 크롭을 수행하는 2단계 파이프라인을 구축했다. 핵심은 관심사 분리(Separation of Concerns)로, Detector는 위치만, 규칙은 크롭 로직을 담당한다. 의류는 강한 공간적 규칙성(Geometric Prior)을 가지므로, 부위별 위치를 예측 가능한 좌표 규칙으로 인코딩하여 VLM의 추론 과정을 생략했다. 이 방식은 모델의 복잡도를 낮추고, 25배 빠른 추론 속도를 달성하는 핵심 요인으로 작용했다. 또한, 카테고리별 테스트셋을 구축하고 PM과의 협업을 통해 귀납적 튜닝(Inductive Tuning)을 진행하여 규칙의 정확도를 높였다.
AWS Lambda를 서빙 인프라로 선택한 배경
AutoCrop API는 검수 시간(09:00~18:00)에만 트래픽이 집중되는 특성을 고려하여, AWS Lambda를 서빙 인프라로 선택했다. Lambda는 요청 시에만 실행되어 유휴 시간 비용(Idle Time Cost)을 절감하고, 팀의 기술 스택(Kotlin/Spring)과 Python 기반 ML 서버 운영 경험 부족을 고려한 현실적인 선택이었다. Docker 컨테이너 기반 배포 및 CPU 전용 PyTorch 사용으로 이미지 크기를 700MB로 최소화했다. Lambda 메모리 할당량에 따라 vCPU가 증가하는 점을 활용, 메모리 8GB 할당으로 추론 시간을 2배 단축하여 응답 속도(Response Time)를 개선했다.
11만 상품 마이그레이션 및 비즈니스 성과
AutoCrop 시스템 구축 후, 신규 상품뿐 아니라 기존 11만 개 상품에도 디테일컷을 일괄 적용했다. Lambda의 Warm 상태 유지를 통해 별도의 배치 인프라 없이 마이그레이션을 완료했다. 디테일컷 추가로 구매자는 상품의 세부 상태를 직접 확인할 수 있게 되었고, 검수 공정에서 상품당 약 63초의 공정 시간 절감 효과를 얻었다. 기술적으로는 VLM 대비 25배 빠른 추론 속도와 10배 낮은 비용을 달성했으며, 10개 의류 카테고리를 지원한다. 이는 AI 기술 도입의 성공적인 사례(Successful AI Adoption)로, 문제의 본질을 파악하고 적합한 도구를 선택한 결과이다.