Aurora PostgreSQL에서 pg_bigm과 pgvector를 활용한 한국어 RAG 시스템 구축
by DD
2개월 전
조회수 40
한국어의 특수성을 고려하여, pg_bigm(키워드 검색)과 pgvector(시맨틱 검색)을 RRF(Reciprocal Rank Fusion)로 결합하는 하이브리드 검색 방식 제안
pg_bigm은 한국어 조사를, pgvector는 의미적 유사성을 기반으로 검색하며, 각 방식의 약점을 보완
Aurora PostgreSQL 환경에서 데이터 수집, 임베딩, 인덱싱, 검색, 응답 생성의 전체 파이프라인을 구축
pg_bigm은 tsvector보다 한국어 단어 검색에서 평균 304% 더 많은 문서를 찾아내며, 하이브리드 검색은 다양한 쿼리 유형에 안정적인 결과 제공
RAG(Retrieval-Augmented Generation) 애플리케이션에서 하이브리드 검색을 통해 검색 품질 향상 및 최종 답변의 정확도 개선
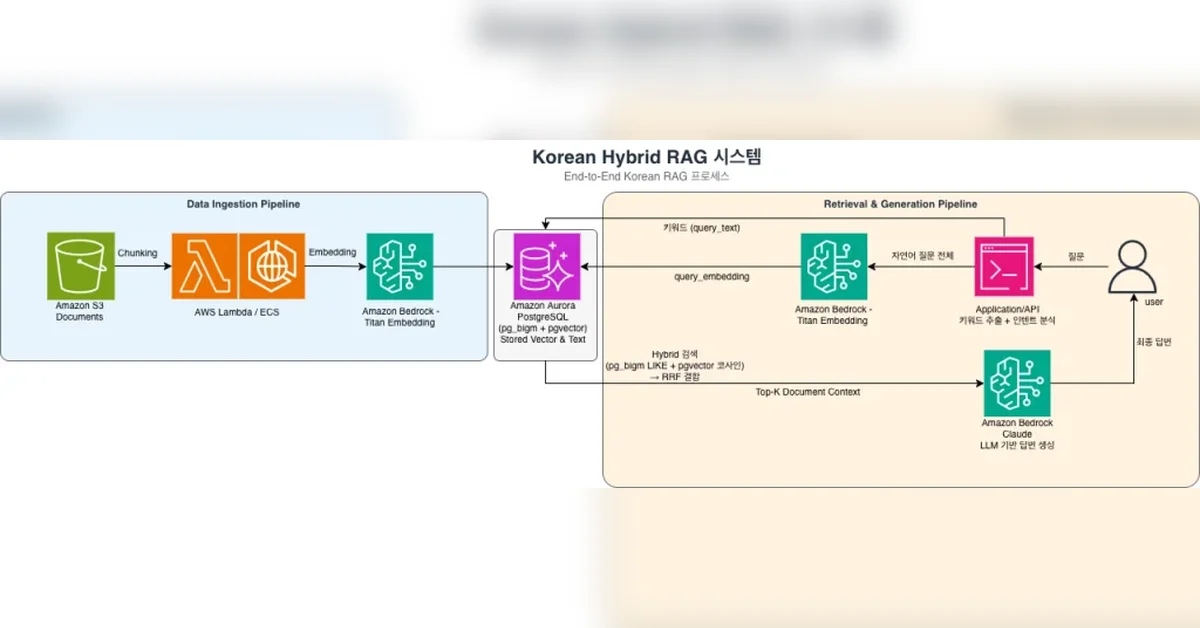
한국어 하이브리드 검색 아키텍처 심층 분석
본 아키텍처는 pg_bigm(키워드 검색)과 pgvector(시맨틱 검색)을 RRF(Reciprocal Rank Fusion)로 결합하여 한국어 RAG 시스템의 검색 정확도를 향상시킨다. 데이터 수집 파이프라인은 AWS Lambda/ECS를 사용하여 S3의 문서를 청킹하고, Amazon Bedrock Titan Embeddings V2를 통해 1024차원 벡터로 변환한다. 변환된 데이터는 Aurora PostgreSQL에 저장되며, pg_bigm GIN 인덱스와 pgvector HNSW 인덱스가 생성된다. 검색 및 응답 생성 파이프라인은 사용자의 질의를 pg_bigm과 pgvector로 분기하여 검색하고, RRF를 통해 결과를 결합하여 최종 답변을 생성한다. 이 아키텍처는 한국어의 특성을 고려하여, 키워드 검색과 시맨틱 검색의 장점을 모두 활용한다.
pg_bigm: 한국어 키워드 검색의 핵심 기술
pg_bigm은 PostgreSQL의 GIN 인덱스(GIN Index)를 활용하여 한국어 바이그램(bigram) 기반 키워드 검색을 지원한다. 기존 tsvector 방식은 한국어 조사를 제대로 처리하지 못하는 반면, pg_bigm은 2글자 단위로 텍스트를 분할하여 인덱싱하므로 조사/어미 변화에 유연하게 대응한다. 예를 들어, “대한민국” 검색 시 “대한민국은”, “대한민국의” 등 다양한 형태의 단어를 모두 검색할 수 있다. pg_bigm은 tsvector보다 평균 304% 더 많은 문서를 찾아내는 성능을 보이며, LIKE 연산자 대신 =% 연산자를 사용하면 GIN 인덱스를 활용한 유사도 기반 필터링이 가능하다. 하지만, GIN 인덱스 특성상 인덱스 크기가 커질 수 있다는 점을 고려하여, 문서 청킹(Chunking) 전략을 적절히 수립해야 한다.
pgvector: 시맨틱 검색을 통한 의미 기반 매칭
pgvector는 HNSW 인덱스(Hierarchical Navigable Small World Index)를 사용하여 임베딩 벡터 간의 코사인 유사도를 계산하여 의미적으로 관련된 문서를 검색한다. pg_bigm이 정확한 키워드 매칭에 강점을 보이는 반면, pgvector는 자연어 질문이나 동의어/관련 개념 매칭에 효과적이다. 예를 들어, “한국 전쟁”에 대한 검색 시 pgvector는 “6.25 전쟁”과 같은 관련 문서를 정확하게 찾아낸다. HNSW 인덱스 튜닝(HNSW Index Tuning)을 통해 검색 품질을 개선할 수 있으며, `ef_search` 값을 조정하여 재현율과 속도 간의 균형을 맞출 수 있다. RAG 환경에서는 `ef_search` 값을 100~200 사이로 설정하는 것을 권장한다.
RRF(Reciprocal Rank Fusion)를 이용한 검색 결과 결합
RRF는 pg_bigm과 pgvector의 검색 결과를 순위(rank) 기반으로 결합하는 알고리즘이다. 각 검색 방식의 점수 스케일이 달라도 공정하게 결합할 수 있다는 장점이 있다. RRF_score는 `Σ weight / (k + rank)` 공식으로 계산되며, k는 스무딩 상수, rank는 각 검색 방식에서의 순위, weight는 키워드/시맨틱 가중치를 의미한다. 하이브리드 검색에서는 키워드 가중치(keyword_weight)와 시맨틱 가중치(semantic_weight)를 조절하여 각 검색 방식의 기여도를 제어할 수 있다. RAG 파이프라인에서는 query_text에 자연어 질문 전체가 아닌 핵심 키워드를 전달하고, 원본 질문은 query_embedding 생성에 사용하는 것이 효과적이다.
Python RAG 애플리케이션 통합 및 Bedrock 활용
본문에서는 Python을 사용하여 Aurora PostgreSQL과 Amazon Bedrock을 연동하는 RAG 애플리케이션을 구현하는 방법을 제시한다. psycopg2 라이브러리를 사용하여 PostgreSQL에 연결하고, pgvector.psycopg2를 통해 벡터 기능을 등록한다. Bedrock Runtime API를 호출하여 텍스트 임베딩을 생성하고, 하이브리드 검색 함수를 호출하여 검색 결과를 얻는다. 최종적으로, 검색된 문서 컨텍스트를 기반으로 Bedrock Claude 모델을 사용하여 답변을 생성한다. Bedrock 임베딩 호출은 지연 시간과 비용이 발생하므로, 프로덕션 환경에서는 자주 사용되는 쿼리의 임베딩을 캐싱하는 것이 권장된다.