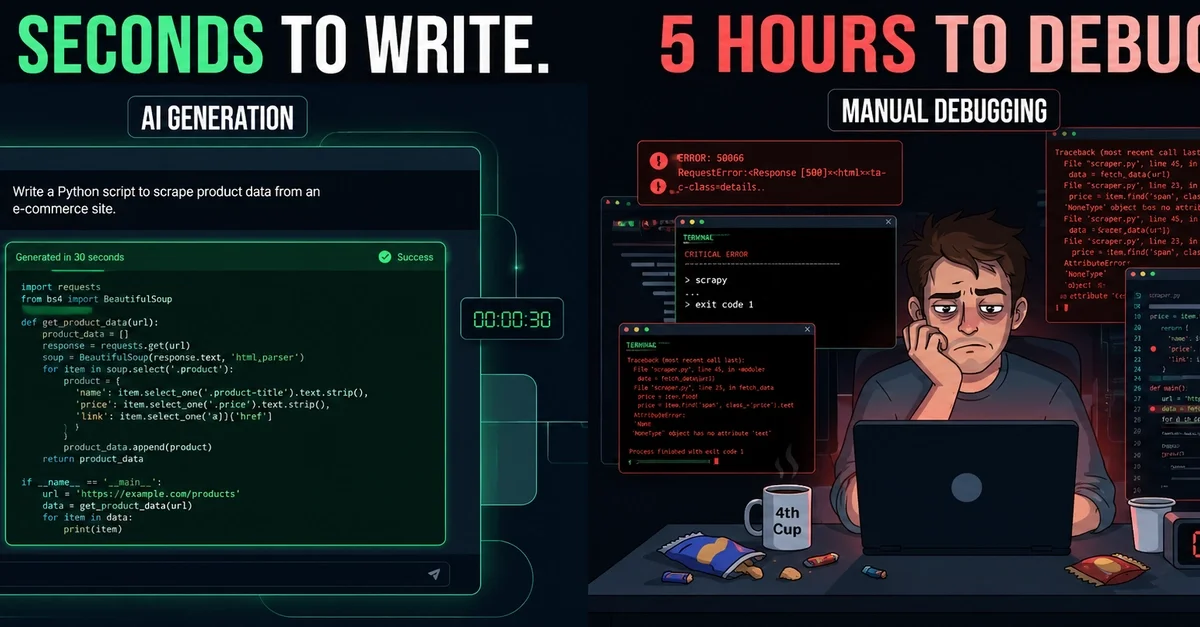
AI 코드, 30초 작성 vs 5시간 디버깅
by DD
1개월 전
조회수 24
AI 코드 생성은 30초 만에 완료되나, 실제 프로덕션 환경에서 발생하는 숨겨진 오류(Hidden Errors) 발견 및 수정에 5시간 이상 소요됨
AI는 행복 경로(Happy Path)만 가정하고 코드를 생성하여, 빈 리스트(Empty List)와 같은 엣지 케이스(Edge Case)에서 예외 처리(Exception Handling) 누락으로 인한 프로덕션 장애 발생
AI 코드의 가독성(Readability) 부족과 불명확한 변수명(Vague Variable Names)은 코드 소유권 및 이해도를 저하시켜 디버깅 시간을 증가시키는 요인으로 작용함
AI 코드의 인지 부하(Cognitive Load) 및 자신감 침식(Confidence Erosion)은 장기적으로 개발 생산성을 저해하며, 기회 비용(Opportunity Cost) 발생을 야기함
AI 코드의 '보이지 않는 가정'과 프로덕션 장애
AI는 사용자의 명시적 요구사항 외에 암묵적인 가정(Implicit Assumptions)을 코드에 포함시키는 경향이 있음. 본문 사례에서는 빈 리스트(Empty List)를 처리하지 않는 가정이 프로덕션 환경에서 실제 사용자 데이터와 충돌하며 장애를 일으킴.
문제점: AI는 실제 운영 환경의 다양한 엣지 케이스(Edge Cases)를 고려하지 않고, 테스트 환경의 에 최적화된 코드를 생성함.