Redshift 데이터 공유, SMUS로 거버넌스와 격리 동시 달성!
대형 리테일 그룹의 데이터 플랫폼 통합 프로젝트에서 자회사별 Redshift 및 ML 워크로드 분리 운영으로 인한 사일로 문제 해결 필요성 대두
소스 컴퓨트 격리, 안전한 데이터 조회, SageMaker Catalog 거버넌스, Redshift 엔진 직접 쿼리 요건 동시 만족하는 패턴 검증
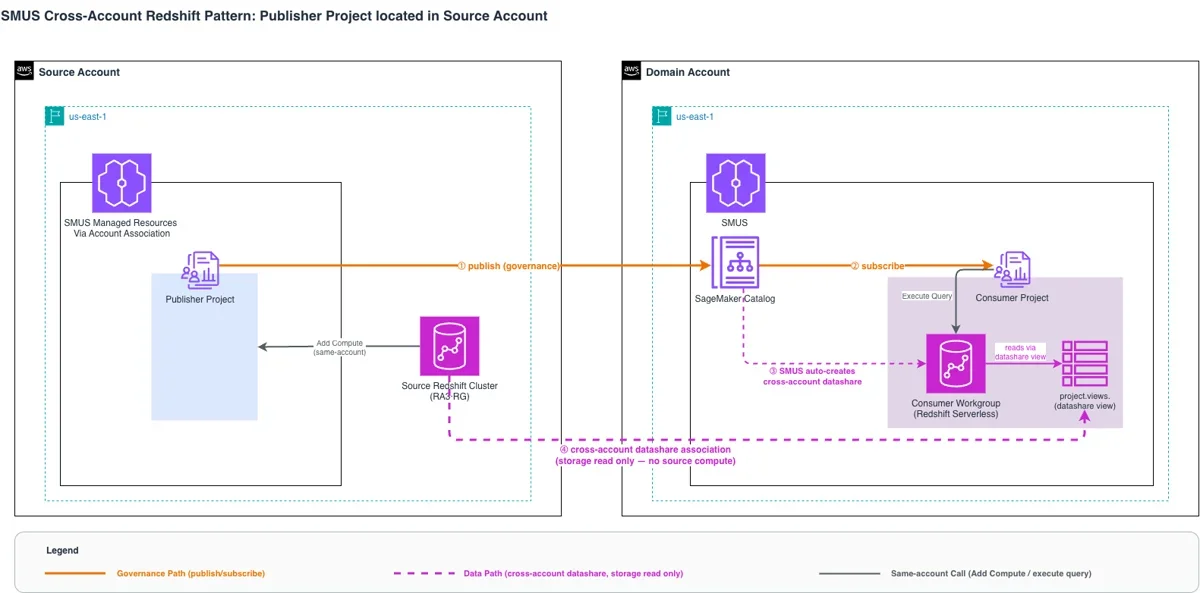
Publisher 프로젝트를 소스 계정에, Consumer 프로젝트를 도메인 계정에 배치하는 권장 패턴이 네 가지 요건 모두 충족함
SMUS publish/subscribe 워크플로우는 Publisher와 소스 데이터가 같은 계정이어야 하며, cross-account는 subscribe 방향만 지원함
권장 패턴은 데이터 격리(Data Isolation)와 거버넌스 통합을 동시에 달성하며, Athena 호환과의 트레이드오프 인지 필요
SMUS Publish/Subscribe 거버넌스의 계정 분리 원칙
본문에서 제시된 세 가지 실패 구성은 SMUS publish/subscribe 거버넌스 워크플로우의 핵심 설계 원칙을 역설적으로 드러낸다. Publisher 프로젝트와 소스 데이터는 반드시 같은 AWS 계정에 있어야 하며, cross-account 접근은 subscribe 방향에서만 지원된다는 점이다. 이 원칙은 자산의 소유권(ownership)과 데이터 공유 권한 부여(grant)가 단일 신뢰 경계(trust boundary) 내에서 완결되도록 하여 감사 추적(audit trail)과 권한 관리를 용이하게 한다. 이 원칙이 깨질 경우, 구성 3에서처럼 거의 모든 단계가 성공하더라도 최종 권한 부여 단계에서 404 오류가 발생하는 등 예측 불가능한 문제가 발생한다. 이는 SMUS의 거버넌스 모델이 데이터 소유권과 자산 소유권의 일치를 전제로 설계되었기 때문이다.
권장 패턴의 컴퓨트 격리 메커니즘 상세
권장 아키텍처는 Redshift Data Sharing의 본래 설계 의도를 활용하여 컴퓨트 격리를 달성한다. Publisher 프로젝트와 소스 Redshift 클러스터가 같은 계정에 위치함으로써, Publisher의 IAM role은 자체적으로 datashare 생성 및 grant 권한을 행사할 수 있다. 이후 Consumer 프로젝트는 도메인 계정의 자체 Redshift Serverless 워크그룹에서 datashare로 grant된 view를 쿼리하게 된다. 이 과정에서 소스 클러스터에는 스토리지 읽기(storage read) 부하만 발생하며, 쿼리 실행 컴퓨팅 자원은 소스 계정에 영향을 주지 않는다. 이는 SMUS Federated Catalog의 JDBC pass-through 모델과 달리, 쿼리 실행 자체가 Consumer 컴퓨트에서 독립적으로 이루어짐을 의미한다. 따라서 소스 컴퓨트의 부하 0 유지라는 핵심 요건을 만족시킨다.
SMUS Federated Catalog 경로의 한계점 분석
SMUS Federated Catalog 경로는 Athena 엔진을 통한 데이터 접근을 가능하게 하지만, 컴퓨트 격리 및 거버넌스 요건 충족에는 한계가 있다. 이 경로는 JDBC pass-through 모델로 작동하여, Athena 커넥터 Lambda가 소스 Redshift 클러스터를 직접 호출하므로 모든 쿼리가 소스 컴퓨트에서 실행된다. 이는 “소스 컴퓨트는 외부에 노출되지 않는다”는 핵심 요건을 위배한다. 또한, Federated Catalog는 SMUS Data Source의 자산 자동 등록 대상에서 제외되어 SageMaker Catalog의 publish/subscribe 워크플로우에 진입할 수 없다. 즉, 데이터 접근은 가능하나 거버넌스 통합 및 컴퓨트 격리라는 두 마리 토끼를 잡기 어렵다는 구조적 제약이 존재한다.
Account-agnostic Project Profile과 Account Pool의 역할
다계정 환경에서 단일 표준으로 그룹 단위 거버넌스를 유지하기 위해 Account-agnostic Project Profile과 Account Pool 기능이 핵심적인 역할을 수행한다. Account-agnostic Project Profile은 프로젝트 생성 시점에 계정 및 리전을 동적으로 선택할 수 있게 하여, 여러 자회사 계정에 동일한 표준 프로파일을 재사용할 수 있게 한다. Account Pool은 이러한 동적 계정 선택지를 미리 정의해두는 리스트로, CLI를 통해 관리된다. 이 기능들을 통해 도메인 소유자는 프로파일을 복제할 필요 없이 여러 자회사에 일관된 거버넌스 정책을 적용할 수 있으며, 신규 자회사 추가 시에도 Account Pool 업데이트만으로 확장이 용이하다. 이는 엔터프라이즈 환경에서 SMUS 거버넌스 운영 부담을 크게 줄여준다.
SageMaker Catalog와 AWS Glue Data Catalog의 차이점
본 패턴에서 사용되는 카탈로그는 SageMaker Catalog이며, 이는 AWS Glue Data Catalog와는 역할이 다르다. SageMaker Catalog는 데이터 검색, 게시/구독 워크플로우, 비즈니스 용어집(business glossary), 데이터 계보(lineage) 등 거버넌스 메타데이터 관리에 특화되어 있다. 반면 AWS Glue Data Catalog는 Athena, Redshift 등 분석 엔진이 쿼리 대상으로 사용하는 기술 메타데이터를 관리한다. 권장 패턴에서 Consumer는 SageMaker Catalog를 통해 자산을 검색하고 구독하며, 쿼리는 Redshift datashare view를 통해 Redshift 엔진에서 실행된다. 따라서 Athena를 통한 직접 쿼리는 불가능하며, 이는 Lake Formation의 Redshift datashare 제약사항과도 일치한다. 즉, SageMaker Catalog는 거버넌스, Glue Data Catalog는 기술 접근에 초점을 맞춘다.
운영 시나리오별 자회사 계정 추가 전략
자회사 계정이 SMUS에 단계적으로 합류하는 환경에서는 Account Pool과 Project Profile의 확장성을 고려한 운영 전략이 필요하다. 만약 계정별 배포 허용 통제가 필요하다면, Account Pool에 신규 계정을 추가하고 Account-agnostic Profile을 사용하는 것이 권장된다. 이는 Profile 자체를 수정할 필요 없이 Pool 업데이트만으로 확장이 가능하며, 이미 배포된 다른 프로젝트에도 영향을 주지 않는다. 반면, 단순히 도메인 association만으로 배포 허용이 충분하다면, 신규 계정을 도메인에 associate하는 것만으로도 동일 Profile에서 선택 가능해져 운영 부담이 가장 적다. 핵심은 Profile은 재사용성을 높이고, 계정 관리는 Pool 또는 association 레벨에서 유연하게 대응하는 것이다.