Cloudflare R2 SQL, 집계 쿼리로 데이터 분석 혁신!
by DD
7개월 전
조회수 12
Cloudflare R2 SQL에서 GROUP BY, SUM 등 집계 쿼리 지원 시작
Scatter-gather 및 Shuffling 방식을 활용하여 대용량 데이터 집계 성능 향상
R2 Data Catalog에 저장된 데이터를 기반으로 보고서 생성 및 이상 징후 탐지 가능
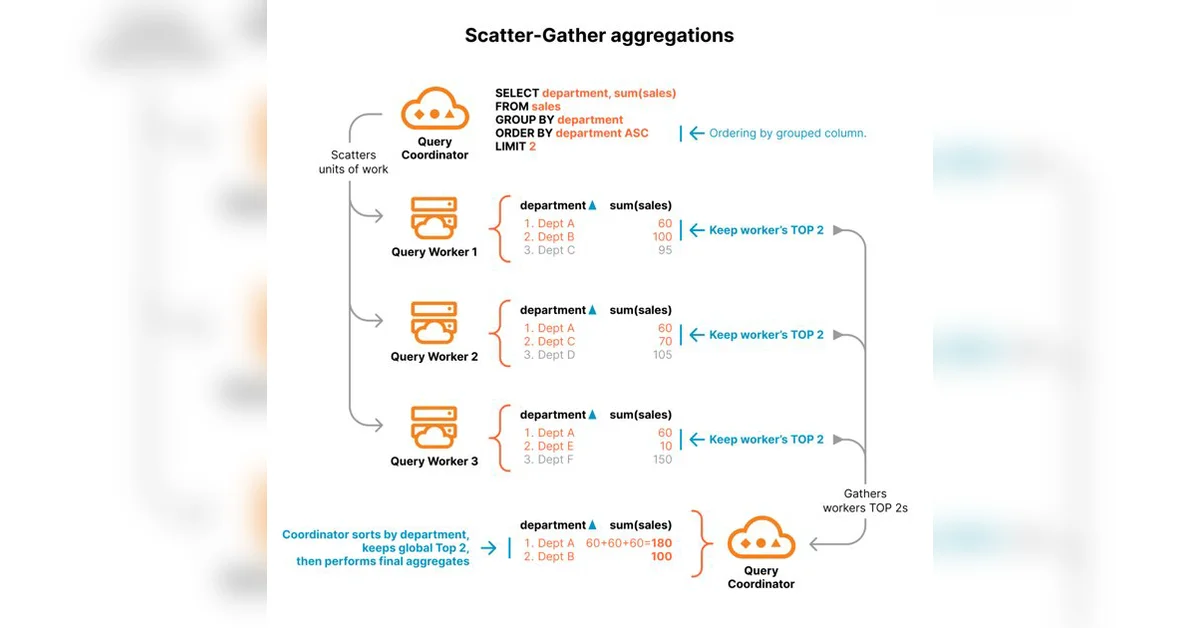
Scatter-gather 방식의 작동 원리
Scatter-gather 방식은 Pre-aggregate를 활용하여 집계 쿼리를 처리한다. 구체적으로, 각 워커 노드는 데이터 부분 집합에 대한 Pre-aggregate를 계산한다. 따라서, **count(*)**의 경우, 각 워커는 로컬에서 행 수를 계산하고, 코디네이터는 이 값들을 더하여 최종 결과를 얻는다.
Shuffling 방식의 장점과 한계
Shuffling 방식은 GROUP BY 컬럼을 기준으로 데이터를 재분배하여, HAVING 및 ORDER BY 절을 효율적으로 처리한다. Deterministic Hash Partitioning을 통해 각 워커는 데이터를 특정 워커로 라우팅한다. 반면, 동기화 장벽으로 인해 모든 워커가 완료될 때까지 대기해야 하는 지연 시간이 발생한다.
R2 SQL의 실전 적용 가이드
대용량 데이터 집계 시, Scatter-gather 방식은 간단한 집계에 적합하다. ORDER BY 또는 HAVING 절을 사용해야 하는 경우, Shuffling 방식을 고려해야 한다. 따라서, LIMIT 쿼리를 활용하여 자원 소비를 최소화하고, 데이터 처리량을 극대화할 수 있다.