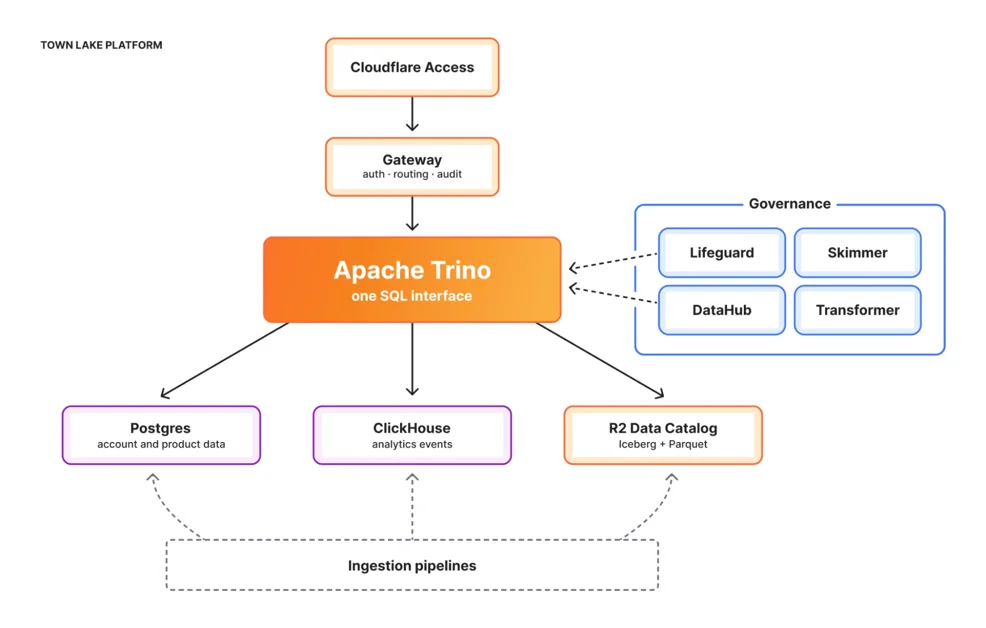
Cloudflare는 데이터 접근성 문제를 해결하기 위해 통합 데이터 분석 플랫폼인 Town Lake를 구축
Town Lake는 Apache Trino를 쿼리 엔진으로 사용하며, R2 Data Catalog와 DataHub를 통해 데이터 관리
AI 데이터 에이전트 Skipper를 통해 자연어 기반 질의를 지원하고, 데이터 접근 권한 및 PII(개인 식별 정보) 보호 기능을 제공
기존 시스템의 복잡성과 데이터 스크롤(Data Sprawl) 문제를 해결하고, 데이터 거버넌스(Data Governance)를 강화
Transformer를 활용하여 셀프 서비스(Self-service) 데이터 엔지니어링 환경을 구축하고, R2 SQL로 워크플로우(Workflow)를 점진적으로 이전
Town Lake는 데이터 레이크하우스(Data Lakehouse) 아키텍처를 기반으로 구축되었으며, Apache Trino를 쿼리 엔진으로 활용하여 다양한 데이터 소스에 대한 통합 쿼리를 지원한다.
R2 Data Catalog: Apache Iceberg를 기반으로 하는 관리형 서비스로, 데이터의 스키마(Schema) 진화, 시간 여행(Time Travel), 파티션(Partition) 관리
DataHub: 모든 테이블, 컬럼(Column), 소유자, 계보(Lineage) 정보 등을 관리하는 메타데이터 카탈로그(Metadata Catalog)
Lifeguard: D1에 접근 규칙을 저장하고, 내부 접근 관리 시스템에서 사용자 및 그룹 멤버십을 동적으로 가져와 Trino이 읽을 수 있는 JSON 정책 생성
이러한 구성 요소들을 통해 Cloudflare는 데이터 격리 아키텍처(Data Isolation Architecture)를 구축하고, 데이터 접근 권한을 세밀하게 제어한다.
Skipper는 자연어 질의를 SQL 쿼리로 변환하고, 결과를 시각화하는 AI 데이터 에이전트이다. Skipper는 Workers, Workers AI, Durable Objects, D1, R2, Workflows, KV 등 Cloudflare의 자체 플랫폼을 기반으로 구축되었다.
Code Mode: 모델이 여러 단계를 거치는 워크플로우(Workflow)를 단일 JavaScript 코드로 표현하여, 모델 호출 횟수(Model Round-trips)를 줄이고 성능을 향상
다중 컨텍스트 레이어(Multiple Context Layers): 스키마 및 사용 메타데이터, 사람의 주석, 코드에서 파생된 지식, 큐레이션된 데이터 모델, 런타임 인트로스펙션(Runtime Introspection) 등 다양한 컨텍스트 레이어를 활용하여 AI 환각(Hallucination)을 방지
데이터 접근 권한: 호출하는 사용자의 권한을 기반으로 작동하며, PII(개인 식별 정보) 접근 시 권한 검사를 수행하여 데이터 보안(Data Security)을 강화
Cloudflare는 데이터 격리 아키텍처(Data Isolation Architecture)를 통해 데이터 거버넌스를 강화하고, 데이터 미저장 정책(Zero-Retention Policy)을 구현하여 보안을 강화했다.
Default-closed 접근 방식: 테이블 접근 권한을 기본적으로 제한하고, 검토를 거쳐 승인된 테이블만 쿼리 가능하도록 설정
Skimmer: PII(개인 식별 정보)를 자동으로 감지하고, 접근 권한을 제어하여 데이터 유출(Data Leakage) 위험 감소
세션 기반 PII 접근: PII가 필요한 경우, 세션(Session) 단위로 접근 권한을 부여하고 모든 쿼리를 로깅(Logging)하여 감사(Auditing) 기능 강화
이러한 접근 방식은 데이터 플랫폼의 안전성을 높이고, 규제 준수(Compliance)를 지원한다.
Transformer는 Cloudflare의 ELT(Extract, Load, Transform) 엔진으로, 사용자가 SQL 변환을 정의하고 배포할 수 있도록 지원한다.
YAML 기반 정의: 사용자는 YAML 파일로 SQL 변환, 대상 테이블, 머터리얼라이제이션(Materialization) 모드, 종속성, 스케줄 등을 정의
Durable Objects: 상태 관리를 위해 Durable Objects를 사용하고, 정의는 R2에 저장하며, 실행 기록은 D1에 저장
자동화된 배포 및 모니터링: 정의된 변환은 자동으로 배포되고, 모니터링되며, DataHub 및 Skipper에 통합
이러한 기능을 통해 Cloudflare는 셀프 서비스(Self-service) 데이터 엔지니어링 환경을 구축하고, 데이터 엔지니어링 생산성을 향상시킨다.
Skipper는 Cloudflare 내부에서 다양한 사용 사례에 활용되며, 데이터 분석 및 문제 해결 시간을 단축한다.
Billing: Billable Usage Dashboard에 사용되며, 53%의 쿼리를 처리하며, 기존 SQL 쿼리 대비 쿼리 라인 수(Query Line) 80% 감소
Business Intelligence: 'Top 100 customers by revenue'와 같은 질문에 대해 3초 이내에 답변을 제공
Security Analytics: Bot Management 팀에서 ML 스코어링 이벤트 분석에 활용
Customer Support: 고객 지원 티켓(Ticket) 관련 데이터 분석에 활용
Skipper는 데이터 접근성을 높이고, 데이터 기반 의사 결정을 지원하여 업무 효율성을 향상시킨다.
Cloudflare는 Skipper의 기능을 확장하고, 데이터 플랫폼을 지속적으로 개선할 계획이다.
Skipper 기능 확장: 내부 채팅 및 티켓 시스템과의 통합을 통해 문제 해결 및 프로젝트 스코핑(Project Scoping) 지원
Transformer 개선: 모든 팀이 SQL 파일과 .meta.json을 사용하여 큐레이션된 데이터 세트를 구축할 수 있도록 지원
R2 SQL 활용: R2 SQL의 기능을 확장하여 Town Lake 워크플로우(Workflow)를 점진적으로 이전
이러한 계획을 통해 Cloudflare는 데이터 플랫폼의 유연성(Flexibility)과 확장성(Scalability)을 지속적으로 향상시키고, 데이터 기반 혁신을 가속화할 것이다.