GraphRAG Toolkit으로, 숨겨진 데이터 연결고리를 찾아보세요!
by DD
1개월 전
조회수 12
벡터 검색(Vector Search)의 한계를 지적하며, 공급망 리스크와 같은 숨겨진 연결 정보를 놓치는 문제를 제시
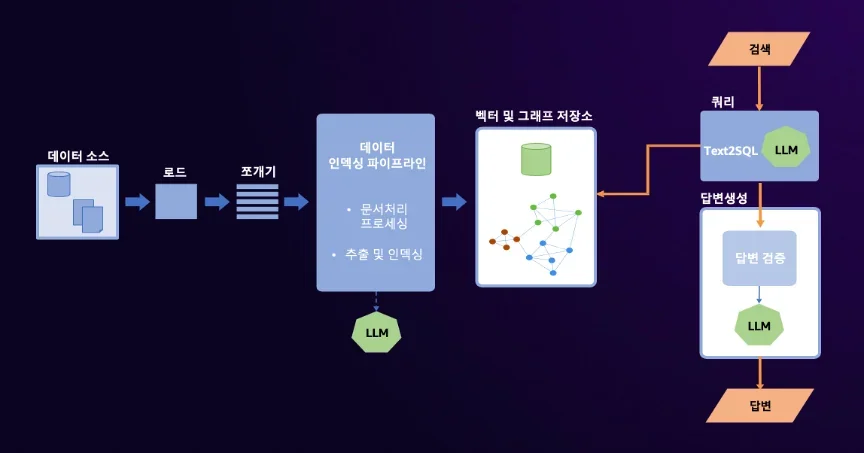
GraphRAG Toolkit은 지식 그래프(Knowledge Graph)를 활용하여 복잡한 관계망 데이터와 숨겨진 연결 정보를 효과적으로 검색
쿼리 프로세스(Query Process)는 질문 임베딩, Top-k 유사도 검색, 그래프 탐색, LLM을 통한 답변 생성으로 구성
TraversalBasedRetriever와 SemanticGuidedRetriever 두 가지 검색기를 제공하며, 데이터 규모와 정확성에 따라 선택
엔티티 네트워크(Entity Network)를 활용하여 비유사성 검색과 프롬프트 강화를 통해 답변 품질을 향상시킴
벡터 검색의 한계와 GraphRAG의 필요성
본문에서는 벡터 검색(Vector Search)이 단어 유사성 기반으로 정보를 검색하기 때문에, 숨겨진 연결 정보를 놓칠 수 있다고 지적한다.
공급망 리스크(Supply Chain Risk): “영국 판매 전망”에 대한 질문에 “운하 막힘”과 같은 구조적으로 관련된 정보(Structurally Related Information)를 찾지 못하는 문제 발생
GraphRAG Toolkit은 지식 그래프(Knowledge Graph)를 활용하여 데이터 간의 복잡한 관계를 파악하고, 비즈니스 의사결정에 필요한 정확한 정보(Accurate Information)를 제공
의사결정의 중요성(Decision Weight): 정보의 정확성과 완전성이 비즈니스 의사결정에 직접적인 영향을 미치는 경우, GraphRAG의 필요성이 더욱 강조됨
GraphRAG Toolkit의 쿼리 프로세스 심층 분석
GraphRAG Toolkit의 쿼리 프로세스는 크게 검색(Retrieve)과 생성(Generate) 두 단계로 나뉜다.
질문 임베딩(Question Embedding): 사용자의 질문을 AI가 이해할 수 있는 수치 형태(Embedding)로 변환
Top-k 유사도 검색(Top-k Similarity Search): 질문의 임베딩과 가장 가까운 상위 k개의 청크(Chunk) ID를 찾음
그래프 탐색(Graph Traversal): 찾은 청크 ID를 시작점으로, 지식 그래프 내 관련 정보를 탐색
LLM 기반 답변 생성(LLM-based Answer Generation): 그래프 탐색 결과와 질문을 LLM에 전달하여 자연어 답변 생성
이러한 쿼리 프로세스를 통해, GraphRAG Toolkit은 단순한 키워드 검색을 넘어 맥락을 이해하는 답변(Context-aware Answer)을 생성한다.
다양한 그래프 탐색 전략: TraversalBasedRetriever vs SemanticGuidedRetriever
GraphRAG Toolkit은 두 가지 고수준 검색기(High-Level Retrievers)를 제공하여, 데이터와 사용자의 요구에 맞는 유연한 검색을 지원한다.
TraversalBasedRetriever: 모든 경로를 체계적으로 탐색하며, 정보 누락을 최소화하고 높은 신뢰도를 제공
SemanticGuidedRetriever: 의미 기반 검색과 구조화된 그래프 탐색을 결합하여, 대규모 데이터에서 빠른 응답 속도를 보장
검색기 선택(Retriever Selection): 데이터 규모, 정확성 요구 사항, 사용자 경험(UX) 등을 고려하여 적합한 검색기를 선택
결과적으로, GraphRAG Toolkit은 다양한 검색 전략을 통해 데이터의 특성과 사용자의 요구(User Needs)에 최적화된 검색 경험을 제공한다.
엔티티 네트워크를 활용한 비유사성 검색
GraphRAG Toolkit은 엔티티 네트워크(Entity Network)를 활용하여, 질문과 직접적인 단어 유사성이 없는 정보도 찾아낸다.
엔티티 네트워크(Entity Network) 정의: 질문에서 추출된 핵심 키워드(엔티티)를 중심으로 1~2단계 연결된 관계망
비유사성 검색(Dissimilarity Search): 엔티티 네트워크를 통해, “영국 판매 전망” 질문에 “운하 막힘”과 같은 구조적 연관 정보(Structural Association)를 찾아냄
프롬프트 강화(Prompt Enhancement): 엔티티 네트워크 정보를 LLM 프롬프트에 포함하여, LLM이 핵심 맥락을 정확히 짚어내는 고품질 응답(High-Quality Response)을 생성하도록 유도
이러한 과정을 통해, GraphRAG Toolkit은 AI 환각(Hallucination)을 줄이고, 더욱 정확하고 완전한 답변을 제공한다.
GraphRAG 시스템의 성능 및 비용 고려 사항
GraphRAG 시스템을 구축할 때, 성능과 비용의 균형을 고려하는 것이 중요하다.
지연 시간(Latency): 그래프 탐색은 여러 단계를 거치므로, TraversalBasedRetriever는 SemanticGuidedRetriever보다 응답 시간이 길 수 있음
인프라 비용(Infrastructure Cost): 그래프(Neptune)와 벡터(OpenSearch) 저장소를 동시에 운영해야 하므로, 벡터 검색만 사용할 때보다 유지 비용이 높음
데이터 규모(Data Scale): 데이터가 방대해질수록 탐색 범위가 넓어지므로, 효율적인 검색기 선택과 파라미터 튜닝이 필수적
결론적으로, 정확성과 완전성이 중요한 비즈니스 의사결정 시나리오에서는 GraphRAG의 추가 비용이 가치가 있지만, 단순한 FAQ 답변이나 문서 조회가 목적이라면 기존 벡터 검색만으로도 충분하다.