자연어 이력서 검색, LLM과 OpenSearch로 정확도 90% 돌파
약 10만 명 번역가 이력서 검색 정확도 향상을 위해 데이터 파이프라인 구축 및 LLM 기반 메타데이터 추출, 환각 검증 등 정제 과정 수행
자연어 쿼리 처리 한계 극복을 위해 복합 조건 처리, DSL 변환 정확도 향상, 하이브리드 검색 최적화 과제 해결
Function Calling + RAG 패턴과 OpenSearch 하이브리드 검색을 통해 nDCG@10 0.901, NL→DSL 변환 정확도 91.7% 달성
검색 정확도 향상으로 프로젝트 PM의 인력 탐색 및 검토 시간 단축, 비즈니스 성과 증대
하이브리드 검색 정규화 및 결합 전략
본 시스템은 BM25 점수와 Vector 점수의 스케일 차이를 극복하기 위해 OpenSearch의 normalization-processor와 search-pipeline을 활용했습니다. Grid Search를 통해 min_max 정규화와 harmonic_mean 결합 방식을 채택했으며, 특히 이력서 검색 도메인에서 의미 유사도(Semantic Similarity)의 중요성을 정량적으로 입증했습니다. 운영 환경에서는 데이터 규모에 따라 균형 가중치(0.4:0.6, arithmetic_mean)를 기본값으로 하고, 키워드 중심 또는 의미 중심의 프리셋을 선택하는 유연한 구조를 적용했습니다.
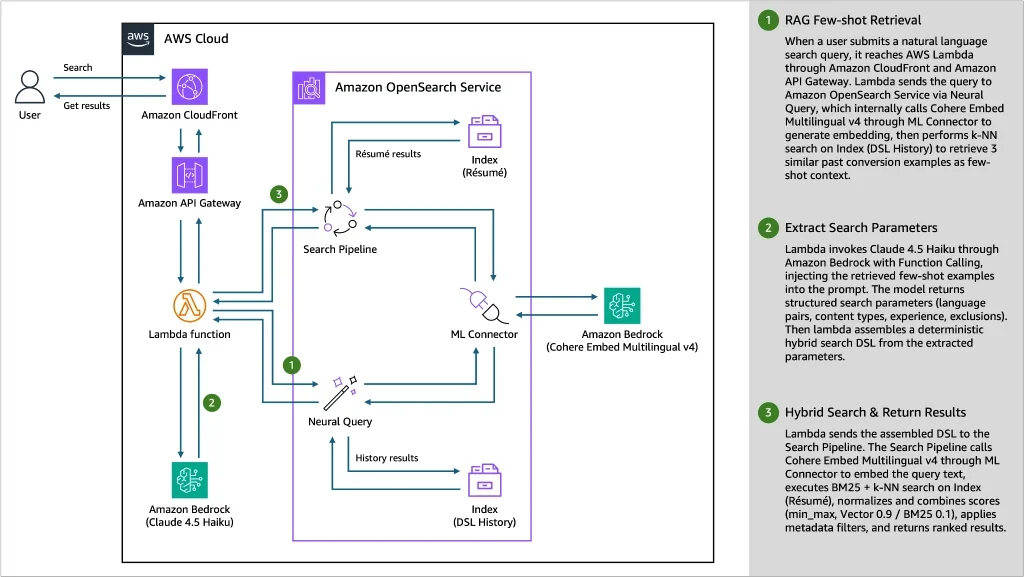
Function Calling + RAG 패턴 기반 NL→DSL 변환
자연어 쿼리를 OpenSearch DSL로 변환하기 위해 LLM의 Function Calling(Tool Use) 기능을 활용하여 검색 파라미터만 추출하고, DSL 조립은 백엔드 코드가 담당하는 결정론적 책임 분리를 채택했습니다. 여기에 RAG 패턴을 도입하여 과거 변환 예시를 Few-shot으로 동적 주입함으로써, 특히 모호한 자연어 표현에 대한 변환 정확도를 베이스라인 대비 +4%p 개선하여 nDCG@10 0.882를 달성했습니다. 이는 LLM의 구조화된 출력(Structured Output) 확보와 정확도 보강에 효과적인 접근 방식입니다.
Agentic Search 대비 Function Calling의 우위
OpenSearch Agentic Search는 하이브리드 검색 불가, 가중치 제어 어려움, 필터 값 검증 부재, 비결정성 등의 구조적 한계로 인해 본 프로젝트의 요구사항을 충족시키지 못했습니다. 반면 Function Calling 방식은 LLM이 추출한 파라미터를 표준 어휘 사전(VALID_VALUES)과 별칭/퍼지 매칭으로 검증·정규화하는 안전망을 구축하여, 존재하지 않는 필터 값 생성 문제를 해결하고 랭킹 품질과 응답 속도에서 우위를 확보했습니다. 이는 LLM의 역할을 명확히 정의하고 결정론적 코드와의 결합이 중요함을 시사합니다.
한국어 복합어 및 표기 정규화 처리
한국어 이력서 검색 품질 확보를 위해 OpenSearch에 Nori 형태소 분석기를 설치하고 인덱스 매핑에 적용했습니다. 복합어 분해(nori_tokenizer mixed decompound), 읽기형 변환(nori_readingform), 품사 기반 필터링 설정을 통해 “게임 로컬라이제이션”, “K-드라마 자막”과 같은 복합어 검색이 정확하게 동작하도록 했습니다. 이는 비정형 한국어 텍스트의 검색 정확도를 높이는 데 필수적인 과정입니다.
평가 데이터셋 구축 및 필터 누적 효과 해결
LLM 생성 쿼리와 실무자 인터뷰 기반 실제 쿼리를 결합한 약 150건의 평가 데이터셋을 구축했습니다. 분석 결과, LLM이 과도하게 많은 필터를 추출할 경우 검색 결과가 급감하는 AND 필터 누적 효과를 발견했습니다. 이를 해결하기 위해 시스템 프롬프트에 “필터 최소화 원칙”을 명시하고, RAG 예시 데이터를 정제하여 확실한 조건만 필터로 사용하도록 조정했습니다. 이로써 실무 사용 쿼리 기준 필터 정확도를 36.4%에서 90.9%로 대폭 개선했습니다.
비즈니스 성과 및 확장성
최종적으로 자연어 검색 정확도 nDCG@10 0.901, NL→DSL 변환 정확도 91.7%를 달성하여 프로젝트 PM의 인력 탐색 및 검토 시간을 단축했습니다. 또한, SSE 기반 점진적 스트리밍으로 체감 응답 속도를 개선했으며, OpenSearch 매니지드 서비스 전환으로 운영 부담을 줄였습니다. 약 10만 명 규모의 번역가 풀 검색을 안정적으로 운영 중이며, 향후 데이터 규모 확장 시 노드 스케일업만으로 대응 가능한 확장성을 확보했습니다.