Qbeast, 데이터 레이크하우스 성능을 혁신하다!
by DD
2개월 전
조회수 10
Qbeast는 데이터 레이크하우스의 읽기 성능 최적화를 위해 설계된 공간 인덱싱 기술임
기존 인덱싱 방식과 달리 쓰기 성능 향상에 초점을 맞춰 데이터 레이아웃을 관리함
파티셔닝(Partitioning) 및 Z-order 방식의 단점을 보완하여 데이터 분포 변화에 유연하게 대응함
OTree 인덱스(OTree Index)를 활용하여 데이터의 공간적 지역성(Spatial Locality)을 유지하고 쿼리 효율성을 높임
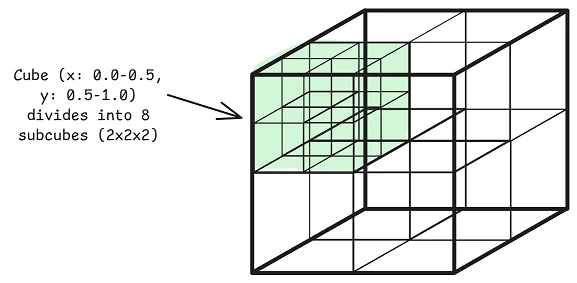
OTree 인덱스(OTree Index)의 작동 원리
Qbeast는 OTree 인덱스(OTree Index)를 사용하여 데이터 레이아웃을 관리하며, 이는 기존의 고정된 파티션 키나 정렬 순서 대신 데이터 분포에 따라 자동으로 세분화되는 하이퍼큐브(Hypercube)를 사용한다. 각 하이퍼큐브는 인덱싱된 열에 의해 정의된 다차원 공간의 영역을 나타내며, 데이터가 추가됨에 따라 적응적으로 세분화되어 데이터의 공간적 지역성(Spatial Locality)을 유지한다. 이러한 방식은 데이터의 분포 변화에 유연하게 대응하며, 불균형한 파티션을 방지한다.
Qbeast와 기존 인덱싱 방식 비교
Qbeast는 기존의 B-tree 인덱스와 의 파티셔닝 및 정렬 방식의 단점을 보완한다. B-tree는 엄격한 키 순서로 모든 행의 위치를 결정하지만, 데이터 세트가 커지고 쿼리가 광범위해지면 비효율적이다. 반면, Iceberg/Delta는 가벼운 메타데이터를 사용하지만, 데이터의 분포 변화에 따라 레이아웃이 최적에서 벗어나는 문제가 있다. Qbeast는 이러한 단점을 보완하여 를 사용하면서도 유연성을 유지한다.