Kafka & Spark Streaming으로 데이터 처리 시간 단축!
by DD
1년 전
조회수 13
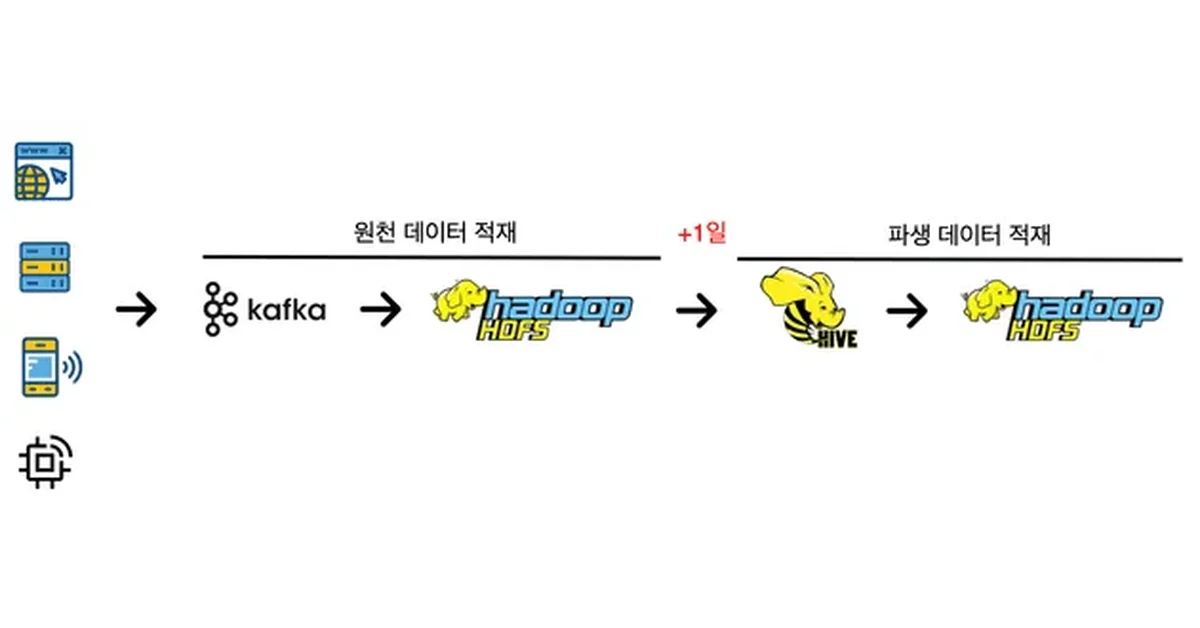
Hadoop 기반 DIC에서 Hive Query를 사용한 배치 방식의 파생 데이터 생성은 +1일 이후에 완료됨
Kafka로 유입되는 데이터를 Spark Streaming을 통해 실시간으로 처리하는 Router 서비스 개발
Spark Streaming을 활용하여 데이터 처리 시간 단축 및 데이터 활용성을 향상시킴
Router 서비스 아키텍처
Router는 Kafka Connect와 Spark Streaming을 활용하여 데이터 파이프라인을 구축한다. 구체적으로 Connect는 다양한 저장소로의 데이터 기록을 담당하고, Spark Streaming은 Kafka 데이터를 변환한다. 따라서 Hive Query 재사용 및 실시간 데이터 처리를 가능하게 하여 데이터 처리 시간을 단축한다.
Spark Streaming을 활용한 실시간 데이터 처리
Spark Streaming은 Yarn 클러스터의 자원 관리 기능을 활용하여 리소스를 효율적으로 사용한다. Kafka로부터 데이터를 가져와 DStream을 생성하고, temp view를 통해 SQL 처리를 수행한다. 반면, 마이크로 배치 방식으로 처리하므로, 데이터 처리량과 지연 시간을 모니터링하는 것이 중요하다.
모니터링 시스템 구축
실시간 데이터 처리 시스템의 안정성을 위해 Spark Job의 정상 수행 여부, 데이터 처리량, Kafka 데이터 지연 여부를 모니터링한다. 구체적으로 Grafana를 사용하여 시각화하고, Burrow를 통해 Kafka Consumer Lag을 측정한다. 따라서 데이터 처리 지연을 사전에 감지하고 대응할 수 있다.