Pinterest, 파운데이션 모델 학습 확장성 7.5배 향상
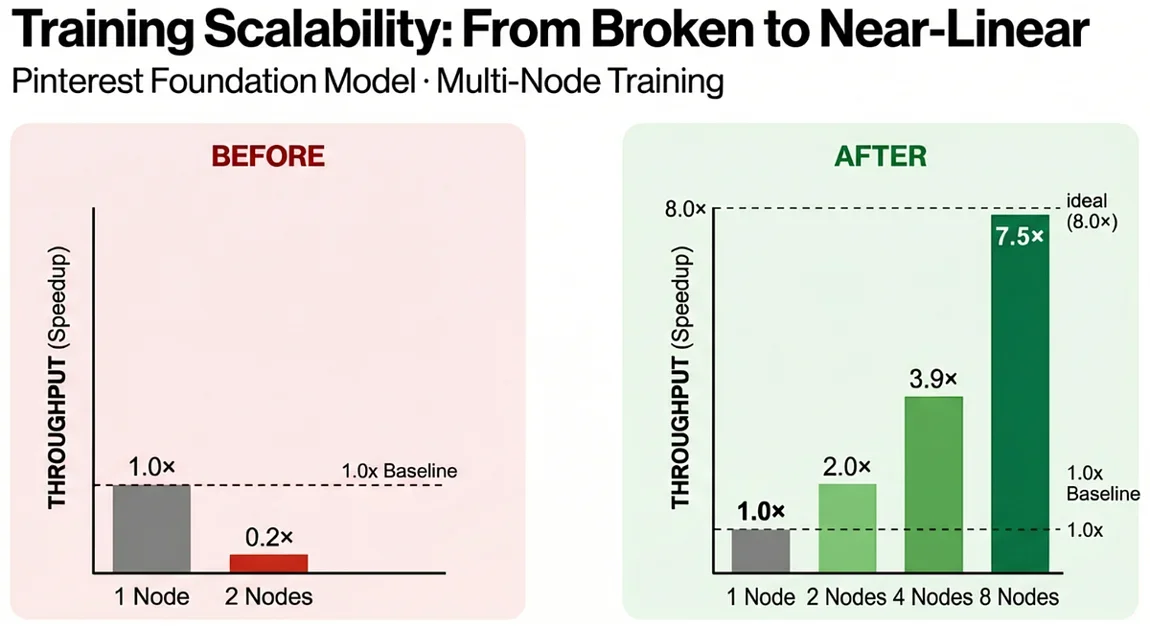
Pinterest는 파운데이션 모델(Foundation Model) 학습 시 확장성 문제(Scalability Issue)에 직면하여 초기 2노드에서 0.2x 성능 저하를 경험함
AWS EFA 도입 후에도 4노드에서 1.21x의 낮은 확장성으로 인해 GPU 활용률 저하(Low GPU Utilization) 및 비용 효율성 문제 발생
QComms, Balanced Sharding, Bandwidth-Aware Embedding 등 다층적 최적화를 통해 4노드에서 3.9x(97.5% 이상)의 근접 선형 확장성(Near-Linear Scalability) 달성
최종적으로 8노드(64 GPU)에서 7.5x 확장성(93.75% 이상)을 확보하여 모델 학습 용량 증대(Increased Model Training Capacity) 및 참여율 향상 견인
초기 확장성 병목: NCCL 통신과 GPU 유휴 시간
초기 단계에서 2노드 학습 시 순방향 전파(Forward Pass) 시간이 73% 증가한 원인은 NCCL 통신 지연으로 인한 GPU 유휴 시간 증가였다. GPU 활용률은 97.7%로 높았으나, SM 효율성은 54.54%에 불과하여 실제 연산보다 네트워크 대기 시간(Network Wait Time)이 지배적이었다. 이는 임베딩 테이블 샤딩(Embedding Table Sharding) 시 발생하는 All-to-All 통신 비용(All-to-All Communication Cost)이 병목의 핵심임을 시사했다.
통신량 감소: QComms와 FP8 양자화
FBGEMM의 양자화 통신 라이브러리(Quantized Communication Library)를 활용하여 FP32에서 FP8으로 통신 페이로드(Payload)를 압축함으로써 데이터 전송량(Data Transfer Volume)을 75% 이상 감소시켰다. 이는 단일 최대 NCCL SendRecv 작업 시간을 크게 단축시켰으며, FP8 양자화가 모델 품질에 영향을 미치지 않음을 검증하여 통신 효율성(Communication Efficiency)을 크게 향상시켰다.
통신 토폴로지 재설계: 2D 병렬 처리 (AllReduce 최적화)
초기 2D 병렬 처리(2D Parallel) 방식은 각 노드 내에서 임베딩 통신을 처리하고 노드 간에는 경량화된 AllReduce로 동기화하는 방식이었다. 이로 인해 통신 작업이 동시에 실행(Concurrent Execution)되며 실효 시간(Effective Wall Time)을 25.68ms에서 16.98ms로 단축하는 성과를 보였다. 이는 통신 병목(Communication Bottleneck)을 노드 로컬(Node-local)로 제한하려는 시도의 첫걸음이었다.
통신 토폴로지 재설계: 2D 병렬 처리 (All-to-All 최적화)
All-to-All 통신이 여전히 병목임을 인지하고 토폴로지를 뒤집었다. 각 노드가 완전한 임베딩 테이블 복제본(Complete Embedding Table Replica)을 보유하고, All-to-All 통신을 노드 내부에서만 수행하도록 변경했다. 이로써 노드 간 통신 비용(Inter-node Communication Cost)을 제거하고, All-to-All 지연 시간을 83% 감소시켜 2노드에서 2.0x, 4노드에서 3.9x의 확장성을 달성했다. 이는 통신 경로 최적화(Communication Path Optimization)의 중요성을 보여준다.
모델 구조 변경: 대역폭 최적화 임베딩
임베딩 차원(Embedding Dimension)을 절반으로 줄이고 행(Row) 수를 두 배로 늘려 총 용량은 유지하면서, All-to-All 통신 시 데이터 전송량(Data Shipped per All-to-All)을 절반으로 감소시켰다. 이 실험은 메모리 용량(Memory Capacity)보다 통신 대역폭(Communication Bandwidth)이 확장성의 핵심 병목임을 명확히 했으며, 결과적으로 확장성 요인을 1.78x(2N) 및 2.8x(4N)까지 끌어올렸다.
최종 결과 및 프로덕션 영향
모든 최적화 기법 적용 후, 8노드(64 GPU) 환경에서 7.5x의 확장성(93.75% 이상)과 490k examples/sec 처리량을 달성했다. 이는 이전 대비 13배의 멀티노드 처리량 향상을 의미한다. 이러한 확장성 확보는 더 크고 깊은 모델 학습을 가능하게 했으며, 결과적으로 홈 피드 및 관련 핀 추천 시스템에서 통계적으로 유의미한 참여율 증가를 이끌어냈다.