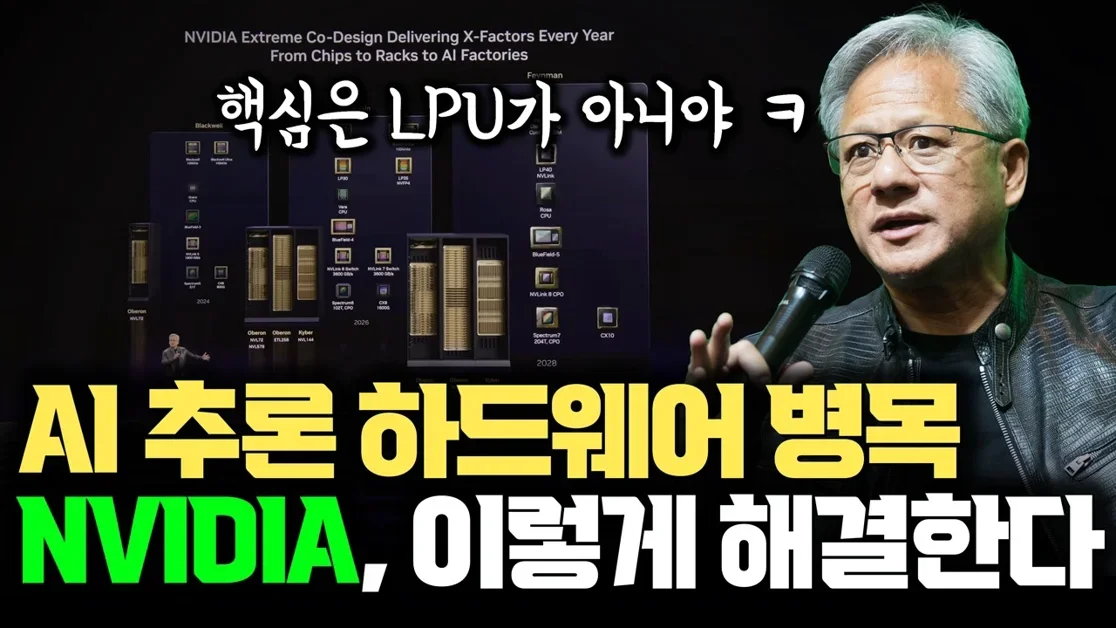
NVIDIA Rubin 아키텍처: AI 추론 병목의 비밀
by DD
4개월 전
조회수 8
NVIDIA의 새로운 아키텍처 Rubin은 LPU보다 메모리 계층화에 중점을 두어 AI 추론 성능을 향상시킴을 강조함
KV 캐시와 MoE(Mixture of Experts) 모델의 특성을 고려한 메모리 시스템 설계의 중요성을 설명함
HBM과 SRAM 등 다양한 메모리 계층을 활용하여 추론 지연 시간(Latency)을 단축하는 방안을 제시함
병렬 처리(Parallelism)와 데이터 접근성(Data Locality)을 최적화하여 AI 모델의 효율성을 극대화하는 아키텍처를 분석함
NVIDIA Rubin 아키텍처와 LPU의 역할
발표자는 NVIDIA의 새로운 아키텍처 Rubin이 LPU(Logic Processing Unit)의 도입을 시사하지만, 핵심은 메모리 계층화 시스템에 있다고 강조합니다. 특히 AI 추론 시 발생하는 병목 현상(Bottleneck)을 해결하기 위해, 기존의 HBM 기반 메모리뿐만 아니라 더 빠른 SRAM을 활용한 계층 구조를 설계하는 것이 중요하다고 설명합니다. 이는 단순히 연산 능력 향상을 넘어, 데이터 접근 속도(Data Access Speed)를 극대화하는 데 초점을 맞추고 있음을 시사합니다.
KV 캐시와 MoE 모델의 메모리 요구사항
영상에서는 AI 모델, 특히 KV 캐시(Key-Value Cache)를 사용하는 모델과 MoE(Mixture of Experts) 아키텍처가 메모리 시스템에 미치는 영향을 분석합니다. KV 캐시는 추론 과정에서 반복적으로 사용되는 정보를 저장하여 지연 시간을 줄이지만, 상당한 메모리 공간을 차지합니다. MoE 모델은 여러 전문가 네트워크 중 일부만 활성화하므로 데이터 접근 패턴(Data Access Pattern)이 복잡해지며, 이에 맞춰 메모리 대역폭(Memory Bandwidth)과 용량(Capacity)을 효율적으로 관리하는 것이 핵심 과제임을 지적합니다.
메모리 계층화: HBM, LPDDR, SRAM의 조합
NVIDIA Rubin 아키텍처는 다양한 메모리 기술을 계층적으로 조합하여 성능을 최적화합니다. 대용량 데이터 처리를 위한 HBM(High Bandwidth Memory), 상대적으로 저렴하고 용량이 큰 LPDDR(Low Power Double Data Rate), 그리고 초고속 접근이 필요한 경우를 위한 SRAM까지, 각 계층의 특성을 활용하여 추론 지연 시간(Inference Latency)을 최소화하고 처리량(Throughput)을 극대화하는 전략을 설명합니다. 이는 마치 CPU의 캐시 계층과 유사한 원리로, 데이터 지역성(Data Locality)을 최대한 활용하려는 시도입니다.
AI 추론 병목 현상과 해결 전략
영상은 AI 추론 시 발생하는 주요 병목 현상이 단순히 연산 능력 부족이 아니라, 메모리 접근 지연(Memory Access Latency)과 데이터 이동(Data Movement)에 있음을 강조합니다. 특히 대규모 언어 모델(LLM)의 경우, 토큰 생성(Token Generation) 과정에서 발생하는 복잡한 메모리 접근 패턴과 KV 캐시의 크기 증가가 성능 저하의 주범이 됩니다. 이를 해결하기 위해 병렬 처리(Parallel Processing)를 강화하고, 데이터를 연산 장치에 더 가깝게 배치(Data Locality)하는 아키텍처 설계가 필수적이라고 설명합니다.
Rubin 아키텍처의 실제 적용 및 성능 향상
NVIDIA Rubin 아키텍처는 이러한 메모리 중심의 최적화를 통해 AI 추론 성능을 크게 향상시킬 것으로 기대됩니다. 특히 초당 처리 가능한 토큰 수(Tokens per Second)와 응답 지연 시간(Response Latency) 측면에서 기존 GPU 대비 상당한 개선을 목표로 합니다. 이는 대규모 언어 모델(LLM)의 실시간 서비스나 복잡한 AI 워크로드에서 사용자 경험(User Experience)을 향상시키는 데 직접적으로 기여할 것입니다. 발표자는 이를 통해 AI 개발 및 배포의 효율성을 높일 수 있다고 전망합니다.