넷플릭스, 멀티모달 AI 모델 MediaFM으로 콘텐츠 이해도 UP!
by DD
4개월 전
조회수 36
넷플릭스는 광범위한 콘텐츠 이해를 위해 오디오, 비디오, 자막을 융합하는 멀티모달 모델(Multimodal Model) MediaFM을 개발
MediaFM은 샷(Shot) 단위의 비디오, 오디오, 텍스트 임베딩(Embedding)을 결합하여 넷플릭스 콘텐츠에 대한 심층적인 이해(Deeper Understanding)를 제공
광고 관련성, 클립 인기 예측, 클립 태깅(Tagging) 등 다양한 애플리케이션에서 기존 모델 대비 성능 향상(Performance Improvement)을 확인
모델의 핵심은 샷 레벨 임베딩의 문맥적 이해(Contextual Understanding)를 위한 트랜스포머(Transformer) 기반 인코더(Encoder)이며, 마스크드 샷 모델링(Masked Shot Modeling)을 활용하여 학습
향후 Qwen3-Omni와 같은 사전 학습된 멀티모달 LLM(Multimodal LLM)을 활용하여 모델 성능을 더욱 향상시킬 계획
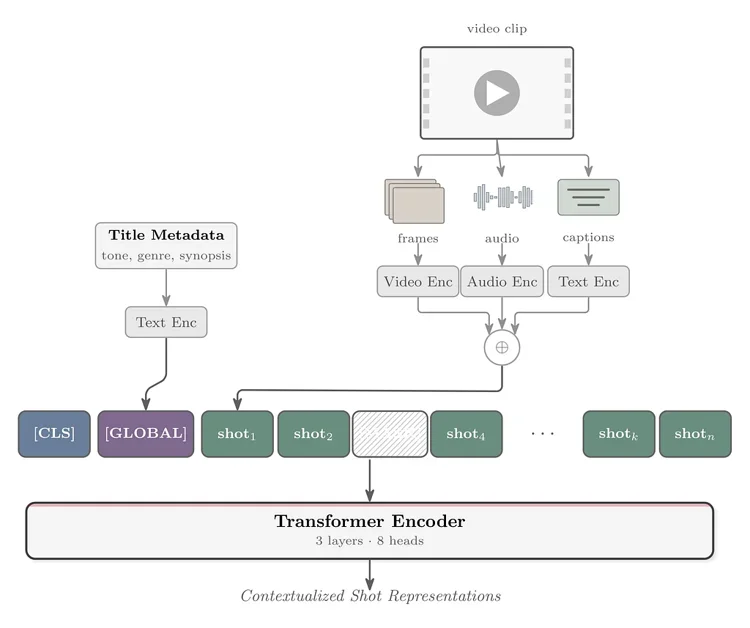
MediaFM의 멀티모달 아키텍처
MediaFM은 넷플릭스 콘텐츠를 이해하기 위해 오디오, 비디오, 텍스트(Audio, Video, Text)의 세 가지 모달리티(Modality)를 융합하는 트랜스포머 기반(Transformer-based) 인코더(Encoder)를 사용한다.
비디오: SeqCLIP(SeqCLIP) 모델을 활용하여 샷(Shot) 단위의 프레임 임베딩 생성