당근마켓, Transformer 기반 유저 임베딩으로 개인화 추천 시스템 성능 대폭 개선
by DD
4개월 전
조회수 54
장기 유저 행동 로그를 활용, 개인화 추천 시스템의 정확도 향상을 위해 Transformer 기반 유저 임베딩(User Embedding) 모델을 개발
유저 임베딩을 홈피드, 광고 등 다양한 추천 모델에 적용하여 클릭률(CTR), 앱 체류 시간(App Session Time) 등 주요 지표를 개선
지역 기반 서비스 특성을 고려, Region-Constrained Batch Sampling(RCBS) 기법을 도입하여 학습 효율(Learning Efficiency)을 높임
콘텐츠 임베딩(Content Embedding) 기반 아이템 표현 방식을 통해 Cold Item 문제 해결 및 GPU 메모리 사용량 최적화
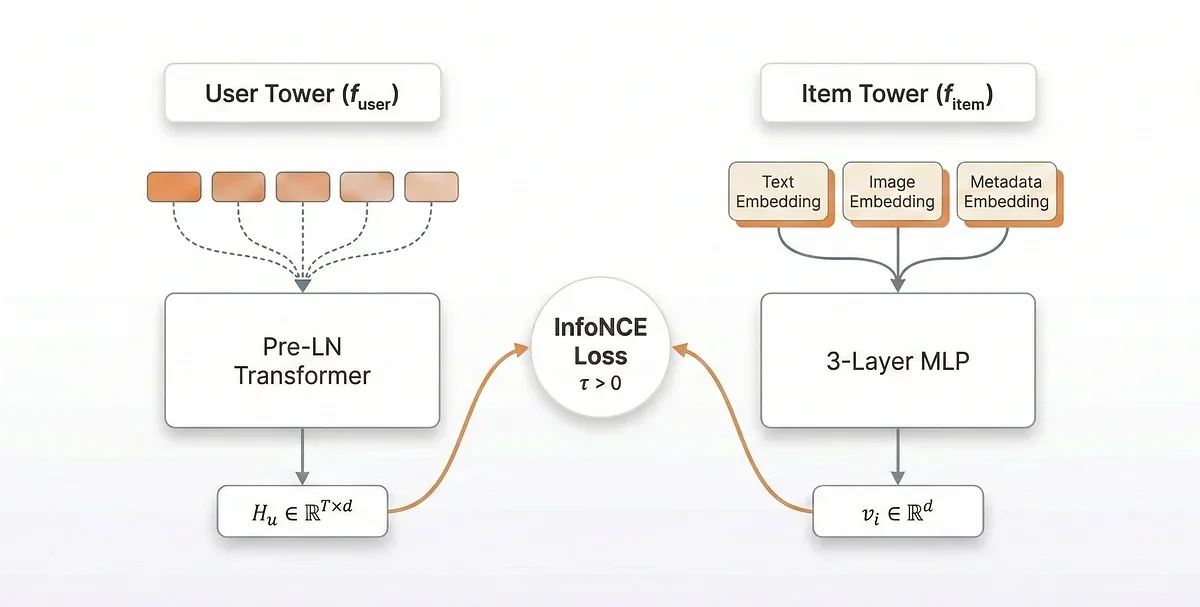
Transformer 기반 유저 임베딩 아키텍처
당근마켓은 장기 유저 행동을 반영하기 위해 Causal Transformer(Causal Transformer)를 활용한 유저 임베딩 모델을 구축했다. 유저의 액션 시퀀스를 입력으로 받아 유저 임베딩을 생성하는 User Tower와 아이템 피처를 입력받아 아이템 임베딩을 생성하는 Item Tower로 구성된 two-tower 구조를 사용했다. 특히, InfoNCE loss(InfoNCE Loss)를 활용한 Contrastive Learning을 통해 유저의 다음 액션을 예측하도록 학습시켰다. 이러한 아키텍처는 유저의 장기적인 취향을 효과적으로 파악하고, 다양한 추천 모델에 적용할 수 있는 유연성을 제공한다.
콘텐츠 임베딩 기반 아이템 표현 방식
장기 유저 모델링에서 아이템 표현 방식은 스케일과 서빙 전략에 큰 영향을 미친다. 당근마켓은 Item ID 임베딩의 Cold Item 문제와 GPU 메모리 제약을 해결하기 위해 콘텐츠 임베딩(Content Embedding) 방식을 채택했다. LLM 기반 임베딩 모델이 생성한 콘텐츠 임베딩을 활용하여, 신규 아이템에 대한 유연성을 확보하고, Transformer의 파라미터 크기를 1,000배 이상 늘릴 수 있었다. Memmap(Memory-Mapped File)과 bbhash(Minimal Perfect Hash)를 조합하여 대규모 콘텐츠 임베딩을 효율적으로 학습에 활용했다.
지역 기반 서비스에 특화된 배치 샘플링(Batch Sampling)
당근마켓은 지역 기반 서비스의 특성을 고려하여 Region-Constrained Batch Sampling(RCBS) 기법을 도입했다. 기존의 랜덤 배치(Random Batch) 방식에서는 유저가 볼 수 없는 아이템이 negative로 사용되는 문제가 발생했다. RCBS는 같은 지역의 유저끼리 배치를 구성하여 Impossible Negatives 비율을 98%에서 30%로 감소시켰다. 이를 통해 Contrastive Learning의 학습 신호의 질을 높이고, Recall@10을 최대 70% 향상시키는 결과를 얻었다. Feasible Negatives를 활용하여 모델의 성능을 더욱 향상시켰다.
온라인 A/B 테스트를 통한 성능 검증
오프라인 실험에서 RCBS-Train (fine) 유저 임베딩의 우수성을 확인한 후, 홈피드 및 광고 후보/랭킹 모델에 적용하는 온라인 A/B 테스트(A/B Test)를 진행했다. 그 결과, 클릭률(CTR), 앱 체류 시간(App Session Time), 광고 매출 등 여러 지표가 trade-off 없이 함께 개선되었다. 특히, 중고거래 채팅, 체류 시간, DAV(Daily Active Viewers)가 증가하여 유저 간의 깊은 연결(Deeper Engagement)을 확인했다. 유저 임베딩 갱신 주기를 24시간으로 설정하여, 성능과 비용 간의 균형을 맞췄다.
RCBS의 기술적 의의와 한계
RCBS는 지역 기반 서비스의 특성을 반영하여 Contrastive Learning의 효율성을 극대화한 혁신적인 방법이다. 기존의 Impossible Negatives 문제를 배치 구성 방식을 변경함으로써 해결했다는 점에서 주목할 만하다. 하지만, 유저 임베딩의 신선도(Freshness) 문제를 해결하기 위해 실시간 추론에 가까워져야 하는 과제가 남아있다. 또한, 다운스트림 태스크에 대한 fine-tuning과 distillation을 통해 User Encoder의 표현력을 극대화하는 연구가 필요하다.