넷플릭스, 초당 1,000만 건 처리하는 그래프 데이터베이스 아키텍처 공개
by DD
1개월 전
조회수 60
넷플릭스는 OLTP(Online Transaction Processing) 사용 사례를 위해 초당 수백만 건의 연산을 처리하는 Graph Abstraction을 개발함
Key-Value(KV) Abstraction을 기반으로 구축되었으며, 실시간 인덱싱(Real-time Indexing), 강력한 타입 지정(Strongly Typed), 효율적인 순회(Traversal)를 지원함
650TB 규모의 그래프 데이터셋(Graph Dataset)에서 1,000만 ops/s 처리, 단일 밀리초(millisecond) 내 응답 속도를 보장하며, 비용 효율성(Cost Efficiency)을 확보함
비동기 삭제(Asynchronous Deletion) 전략으로 노드 삭제 시 결과적 일관성(Eventual Consistency)을 유지하며, 멀티 리전(Multi-Region) 환경에서 데이터 일관성을 확보함
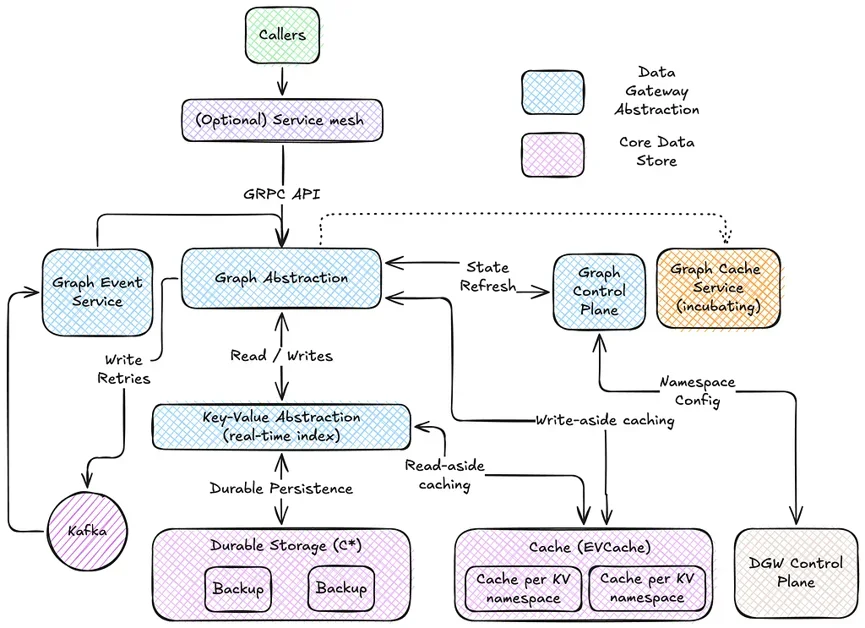
넷플릭스 그래프 추상화(Graph Abstraction) 아키텍처 심층 분석
넷플릭스의 그래프 추상화(Graph Abstraction)는 Key-Value(KV) Abstraction을 기반으로 구축되어, 노드(Node)와 엣지(Edge)의 최신 뷰(View)를 저장하며 실시간 인덱스(Real-time Index) 역할을 수행한다. TimeSeries(TS) Abstraction을 선택적으로 사용하여 데이터의 역사적 뷰(Historical View)를 제공하며, EVCache를 통해 밀리초(millisecond) 단위의 지연 시간(Latency)을 달성한다. 또한, Data Gateway Control Plane과 통합되어 그래프 스키마(Graph Schema) 관리 및 데이터셋(Dataset)의 프로비저닝(Provisioning), 삭제(Deletion), 구성(Configuration)을 자동화한다. 이 아키텍처는 고가용성(High Availability)을 위해 설계되었으며, 넷플릭스 생태계 내 다양한 사용 사례를 지원한다.
고성능 그래프 순회(Traversal)를 위한 최적화 기법
넷플릭스 그래프 추상화(Graph Abstraction)는 Property Graph 모델을 사용하여 데이터를 저장하며, 각 노드(Node)와 엣지(Edge)는 타입이 지정된 속성(Property)을 갖는다. Edge Mapping을 통해 노드 타입 간의 관계를 정의하고, Graph Schema를 활용하여 쿼리(Query) 계획을 최적화한다. 특히, 스키마(Schema)는 데이터 품질(Data Quality) 보장, 쿼리 팬아웃(Query Fanout) 최소화, 중복 경로 제거(Deduplication), 불가능한 경로 제거(Eliminating Traversal paths)에 기여한다. 또한, gRPC 기반의 커스텀 API를 제공하여 Gremlin과 유사한 방식으로 분산 그래프를 탐색할 수 있도록 지원한다.
실시간 인덱싱(Real-Time Indexing)을 위한 KV Abstraction
넷플릭스 그래프 추상화(Graph Abstraction)는 KV Abstraction을 활용하여 노드(Node)와 엣지(Edge)에 대한 실시간 인덱스(Real-time Index)를 구축한다. 각 네임스페이스(Namespace)는 기본 스토리지 계층의 테이블과 연결되며, 데이터는 고유 ID(Unique ID)를 기준으로 파티셔닝(Partitioning)된다. Idempotency를 보장하여 요청 재시도(Request Hedging)를 안전하게 수행하며, Last-Write-Wins(LWW) semantics를 통해 데이터 일관성을 유지한다. 노드(Node)는 자체 KV 네임스페이스(Namespace)에 저장되어 효율적인 읽기(Read)를 지원하며, 엣지(Edge)는 링크(Links)와 속성(Properties)을 별도의 인덱스로 관리하여 개별 속성 업데이트(Property Upserts)를 최적화한다.
캐싱(Caching) 전략 및 일관성(Consistency) 보장
넷플릭스 그래프 추상화(Graph Abstraction)는 Write-aside Caching과 Read-aside Caching 두 가지 캐싱 전략을 사용한다. 엣지 링크(Edge Link)는 짧은 기간 동안 캐싱(Caching)되어 불필요한 쓰기(Write)를 방지하며, EVCache를 활용하여 속성(Property) 데이터를 캐싱(Caching)하여 읽기 증폭(Read Amplification) 문제를 해결한다. Invalidation on write 전략을 통해 캐시(Cache) 일관성을 유지하며, TTL-driven invalidation을 통해 데이터의 유효성을 관리한다. 또한, Kafka 기반의 재시도 메커니즘(Retry Mechanism)을 통해 쓰기(Write) 작업의 실패를 처리하고, 비동기 삭제(Asynchronous Deletion)를 통해 노드 삭제(Node Deletion) 시 지연 시간(Latency)을 최소화한다.
실제 운영 환경에서의 성능 지표
넷플릭스 그래프 추상화(Graph Abstraction)는 650TB 규모의 데이터셋(Dataset)에서 초당 1,000만 건의 연산을 처리하며, 단일 밀리초(millisecond) 내의 응답 시간을 보장한다. 엣지(Edge)와 노드(Node)의 영속성(Persistence)은 단일 밀리초(millisecond) 단위의 지연 시간(Latency)을 달성하며, 1-홉(hop) 순회(Traversal)는 단일 밀리초(millisecond) 내에 실행된다. 2-홉(hop) 순회(Traversal)의 경우, 90번째 백분위수(p90) 지연 시간(Latency)이 50ms 미만으로 유지된다. 또한, 비동기 삭제(Asynchronous Deletion)와 같은 비동기 작업(Asynchronous Operation)은 일반적으로 1초 미만의 지연 시간(Latency)으로 수행된다. 이러한 성능은 넷플릭스의 다양한 사용 사례에서 고가용성(High Availability)을 유지하는 데 기여한다.