넷플릭스, 카산드라 데이터 이동 최적화로 비용 절감 및 성능 혁신
넷플릭스는 카산드라(Cassandra) 기반 데이터 이동(Data Movement)의 복잡성과 확장성 한계를 해결하기 위해 기존 Casspactor 시스템을 개선함
카산드라 분석(Cassandra Analytics) 및 Move Data 프레임워크를 기반으로 한 새로운 아키텍처는 S3에서 직접 데이터를 읽어 Spark DataFrame으로 변환함
데이터 격리 아키텍처(Data Isolation Architecture)와 커넥터 팩토리(Connector Factory) 모델 도입으로 성능 향상, 비용 절감, 유지보수성 개선을 달성함
검증(Validation), 가시성(Visibility), 안전성(Safety) 세 가지 핵심 기둥을 중심으로 무중단 마이그레이션(Zero-Impact Migration)을 성공적으로 수행함
Casspactor의 한계점과 새로운 아키텍처의 필요성
기존 Casspactor 시스템은 메타데이터 의존성(Metadata Dependency)이 복잡하고 파편화되어 있어 데이터 불일치 및 작업 실패를 야기했음. 또한, 데이터 모델 비인지(Data Model Unawareness)로 인해 원시 카산드라 테이블(Raw Cassandra Table)을 그대로 이동시켜 후처리 복잡성이 증가하고, 중간 테이블(Intermediate Table) 비대(Bloat)로 인한 스토리지 비용 증가 및 타임 워프(Time Travel) 기능 부재 등의 문제를 안고 있었음. 이러한 제약은 다양한 카산드라 데이터 추상화(Data Abstraction) 요구사항을 충족시키기 어려웠기에, S3에서 직접 데이터를 읽고 Spark DataFrame을 생성하는 새로운 엔진 기반의 계층형 아키텍처(Layered Architecture)로의 전환이 필수적이었음.
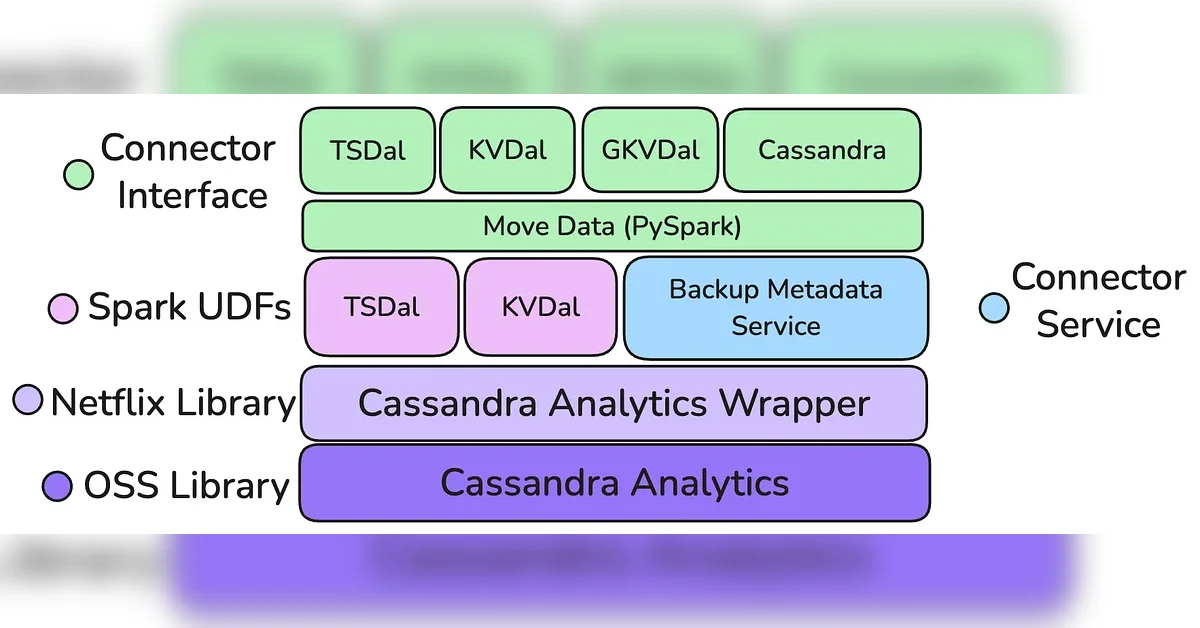
새로운 스택의 계층형 아키텍처와 이점
새로운 아키텍처는 카산드라 분석(Cassandra Analytics) 래퍼를 기반으로 S3에서 원시 데이터를 읽어 표준 Spark DataFrame으로 변환하는 핵심 레이어를 제공함. 이 위에 커넥터 팩토리(Connector Factory) 모델을 통해 각 데이터 추상화(Key Value, Time Series 등)에 최적화된 데이터 모델 인지(Data Model Aware) 커넥터를 개발할 수 있음. 이 구조는 기존 Casspactor의 모놀리식 설계(Monolithic Design)를 탈피하여 재사용성과 유지보수성을 높였으며, 스파크 실행기(Spark Executor) 레벨에서 불균형 파티션 처리(Skewed Partition Handling)를 가능하게 하여 대규모 데이터셋의 안정적인 이동을 보장함. 또한, 중간 테이블 제거로 스토리지 비용을 수백만 달러 절감하는 효과를 가져옴.
무중단 마이그레이션을 위한 3대 핵심 기둥
넷플릭스는 카산드라(Cassandra) 데이터 이동 시스템을 성공적으로 전환하기 위해 검증(Validation), 가시성(Visibility), 안전성(Safety)이라는 세 가지 핵심 기둥을 중심으로 마이그레이션 전략을 수립했음. 섀도우 테스트(Shadow Testing)를 통해 신규 시스템과 기존 시스템 간의 데이터 일관성(Data Consistency)을 100% 보장하고, 중앙 집중식 대시보드와 실시간 알림으로 마이그레이션 진행 상황 및 시스템 상태를 투명하게 추적했음. 특히, 마에스트로(Maestro) 워크플로우 오케스트레이션 플랫폼 내 디사이더 패턴(Decider Pattern)을 활용하여 사용자 인터페이스와 데이터 계약을 동일하게 유지하면서, 신규 시스템 실패 시 자동으로 기존 시스템으로 전환하는 안전망(Safety Net)을 구축하여 제로 임팩트(Zero Impact) 전환을 실현했음.
데이터 모델 인지 커넥터와 성능 향상
새로운 아키텍처는 Spark DataFrame을 중심으로 데이터 처리 방식을 혁신했음. 이전 Casspactor 시스템은 원시 카산드라 테이블을 이동시킨 후 각 데이터 추상화별로 후처리 과정을 거쳐야 했으나, 새로운 커넥터 팩토리(Connector Factory) 모델은 데이터 모델 인지(Data Model Aware) 커넥터를 통해 이러한 복잡성을 제거함. 예를 들어, Key Value 및 Time Series 커넥터는 각 데이터 모델의 특성을 이해하고 최적화된 변환을 수행하여 후처리 비용(Post-processing Cost)과 복잡성을 크게 줄임. 또한, 스파크 실행기 레벨에서 불균형 파티션 처리(Skewed Partition Handling)를 효율적으로 수행하고, 자동 크기 조정(Auto-sizing) 기능을 통해 리소스 사용량을 동적으로 조절함으로써 전반적인 데이터 이동 실행 시간과 비용을 절감함.
S3 기반 메타데이터 관리와 신뢰성 강화
기존 Casspactor 시스템은 여러 독립적인 시스템에서 메타데이터를 조합하여 백업 상태를 파악했기 때문에 메타데이터 동기화 문제(Metadata Synchronization Issues)가 빈번했음. 새로운 아키텍처는 이 문제를 해결하기 위해 Amazon S3를 백업 파일의 단일 진실 공급원(Single Source of Truth)으로 활용함. 백업 파일 자체에서 메타데이터를 직접 읽어 백업의 존재 여부, 완료 상태, 포함된 내용을 정확하게 파악함. 이는 취약한 다중 서비스 의존성(Fragile Multi-service Dependency)을 제거하고 데이터 이동의 신뢰성과 일관성을 크게 향상시킴. 또한, 시간 여행(Time Travel) 기능을 지원하여 특정 시점의 스키마, 토폴로지, 데이터를 일관되게 처리할 수 있게 되어 감사, 디버깅, 재해 복구에 필수적인 기능을 제공함.