X(트위터)의 트윗 서비스, 어떻게 수억 개의 트윗을 처리할까?
by DD
8개월 전
조회수 3
X(트위터)의 트윗 서비스 설계를 통해 확장성, 신뢰성 확보 방안을 제시함
API 게이트웨이, 데이터베이스, 객체 저장소, 메시지 큐 등 다양한 기술을 활용하여 트윗 처리 과정을 설명함
캐싱 전략을 통해 트윗 조회 성능을 개선하고, 데이터베이스 부하를 줄임
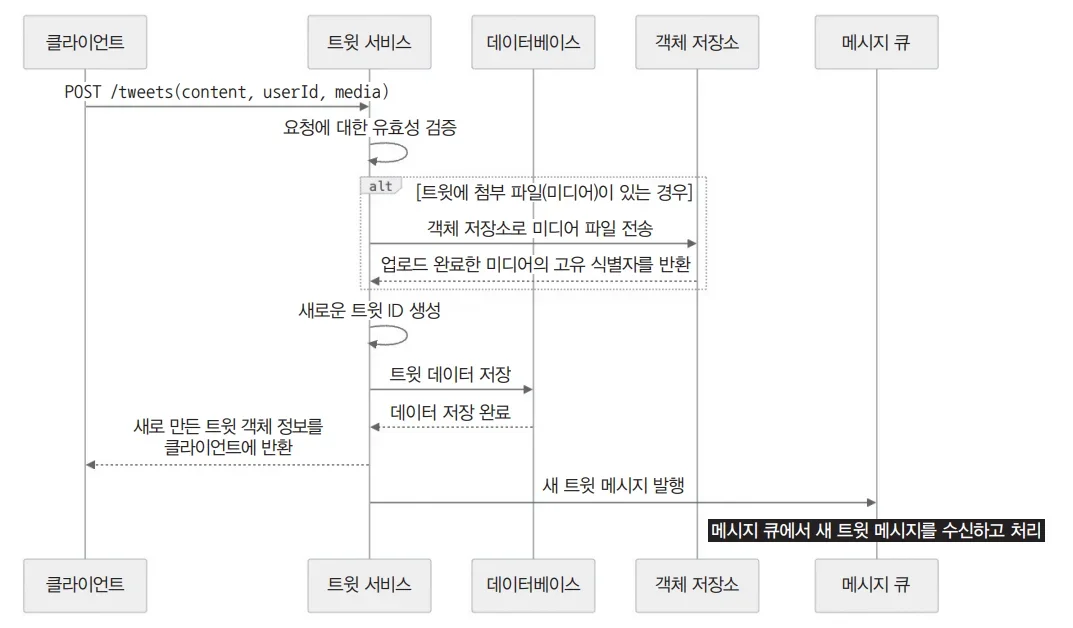
트윗 서비스 아키텍처 심층 분석
트윗 서비스는 API 게이트웨이를 통해 요청을 받아 트윗 데이터베이스에 저장한다. 구체적으로 아파치 카산드라 또는 아마존 DynamoDB를 활용하여 트윗 데이터를 관리한다. 따라서 객체 저장소(S3)에 미디어 파일을 저장하고, 메시지 큐(Kafka)를 통해 비동기적으로 처리한다.
캐싱 전략: 성능 향상의 핵심
X(트위터)는 Redis와 같은 캐싱 시스템을 활용하여 트윗 조회 성능을 향상시킨다. 구체적으로 최근 트윗 캐싱, 인기 트윗 캐싱 등 다양한 전략을 사용한다. 반면, 캐시 무효화 및 일관성 유지를 위해 캐시 버전 관리가 필요하며, 데이터베이스 부하 감소를 달성한다.
확장성과 데이터 무결성 확보 방안
트윗 서비스는 수평적 확장을 통해 트래픽 증가에 대응한다. 따라서 데이터베이스 파티셔닝과 캐시 계층 분리를 통해 성능을 최적화한다. 결과적으로 데이터 무결성을 유지하면서 대규모 트래픽 처리가 가능하며, 서비스 안정성을 확보한다.