Netflix, Druid 쿼리 성능 개선을 위한 똑똑한 캐싱 기술 도입
by DD
3개월 전
조회수 38
Druid 기반 실시간 데이터 분석 시스템의 쿼리 부하 증가로 인해 확장성(Scalability) 문제 발생
인터벌(Interval) 기반 캐싱 기술을 도입하여 쿼리 구조를 이해하고, 중복 쿼리(Duplicate Query)를 캐싱하여 Druid 부하 감소
캐싱 도입 후 Druid 쿼리량 33% 감소, 전체 쿼리 응답 시간(Query Response Time) 66% 개선, 성능 향상(Performance Improvement)을 확인
최신 데이터(Fresh Data)의 지연 시간(Latency)을 최소화하기 위해, 데이터의 시간에 따라 지수적 TTL(Exponential TTL) 적용
향후 Druid 내장 기능으로 통합하여 오픈소스 커뮤니티(Open Source Community)에 기여할 계획
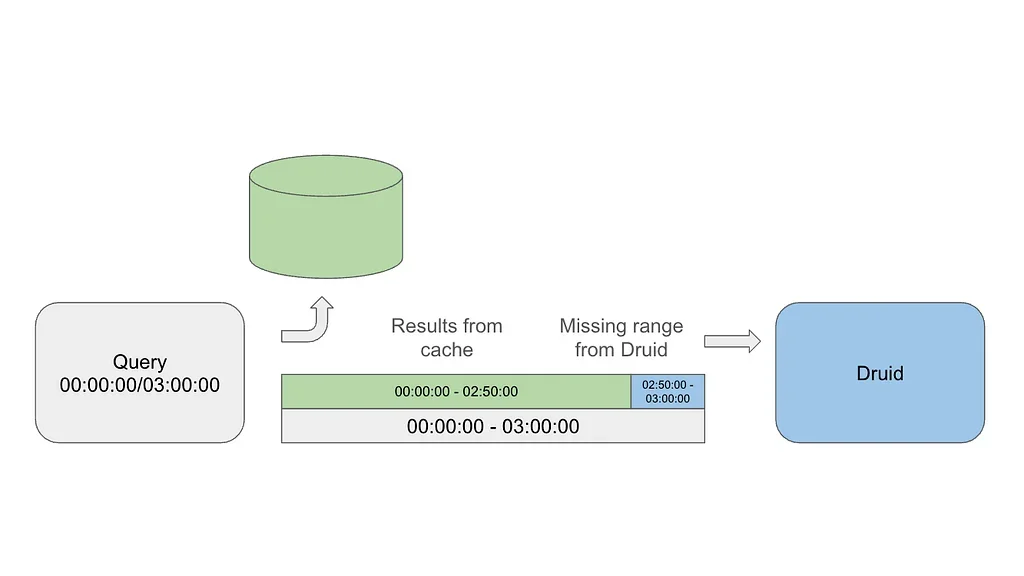
인터벌(Interval) 기반 캐싱 아키텍처
본문에서는 넷플릭스(Netflix)가 Druid 쿼리 성능 개선을 위해 인터벌(Interval) 기반 캐싱을 도입한 아키텍처를 설명한다. 기존 Druid의 캐싱 방식은 쿼리 전체를 캐싱하여, 시간 범위가 조금만 변경되어도 캐시 미스(Cache Miss)가 발생하는 문제가 있었다. 이를 해결하기 위해 쿼리 구조를 이해하고, 시간 간격(Time Interval)을 기준으로 데이터를 독립적인 버킷(Bucket)으로 분할하여 캐싱한다. 특히, 쿼리 해시(Query Hash)를 캐시 키(Cache Key)로 사용하고, 시간 단위(Time Granularity)로 버킷을 나누어 부분적인 캐시 적중(Partial Cache Hit)을 가능하게 했다. 이러한 아키텍처는 쿼리 재사용성을 높이고, Druid의 부하를 줄이는 데 기여한다.