LLM 기반 이력서 평가, 과연 공정할까?
HackerRank가 오픈소스로 공개한 ATS는 LLM을 활용한 이력서 평가 방식으로 주목받음
비결정적 점수 편차(Score Variance)와 평가 기준의 모호성이 주요 문제점으로 지적됨
데이터 미저장 정책(Zero-Retention Policy) 부재 시 개인정보 유출 위험에 대한 우려도 제기됨
AI 환각(Hallucination) 현상으로 인해 실제 역량과 무관한 평가 결과가 나올 수 있다는 비판이 있음
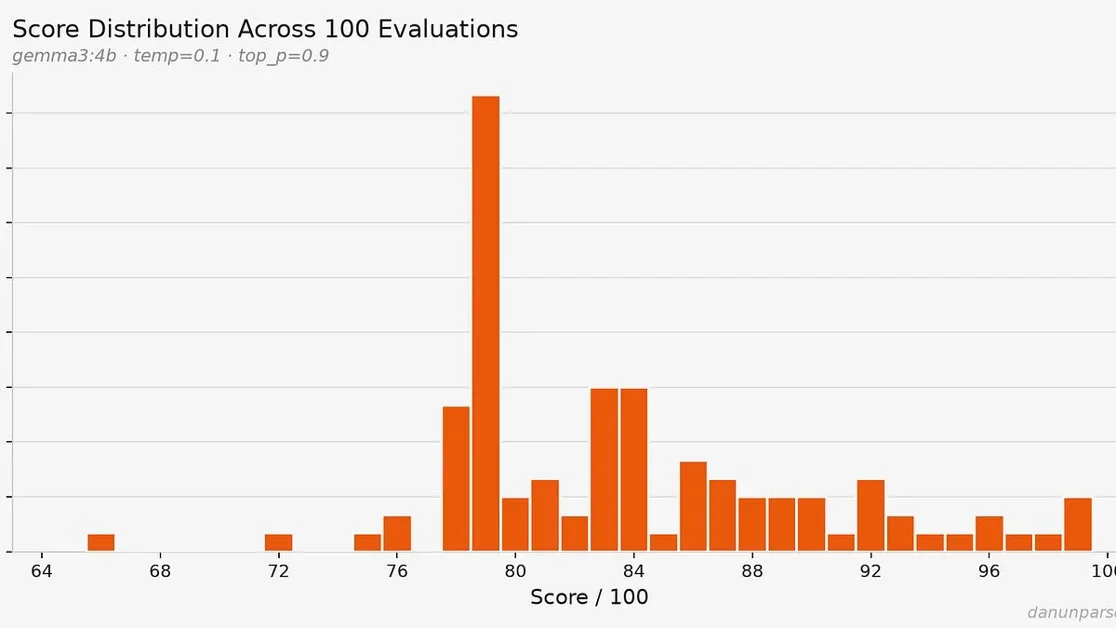
LLM의 비결정성(Non-determinism)과 평가 신뢰도
커뮤니티에서는 Gemma 3:4b 모델의 온도(Temperature) 설정값이 낮음에도 불구하고, 동일한 이력서에 대해 66점에서 99점까지 점수 편차가 발생하는 현상을 지적함. 이는 LLM의 확률적(Stochastic) 특성 때문이며, 데이터 격리 아키텍처(Data Isolation Architecture) 없이 동일 입력에 대해 다른 출력을 내는 것은 비효율적인 컴퓨팅(Waste of Electricity)이라는 비판이 있음. 특히 AI 환각(Hallucination)으로 인해 실제 역량과 무관한 평가가 이루어질 수 있다는 우려가 제기됨.
평가 기준의 모호성과 '운'의 개입
특히 '프로젝트' 및 '경력' 항목의 평가 기준이 모호하고 구체적인 루브릭(Rubric)이 부족하다는 점이 문제로 지적됨. 예를 들어, 주니어 엔지니어와 시니어 엔지니어의 경력 점수가 동일하게 만점(25/25)을 받는 등 변별력이 없음. 이는 무작위 점수 할당(Random Score Assignment)과 다름없으며, '운'에 따라 합격 여부가 결정되는 상황을 초래한다고 비판함.
AI 채용 도구의 법적 및 윤리적 문제
EU 규제 관점에서 볼 때, AI 기반 이력서 필터링은 차별 금지법 위반 소지가 크다고 지적됨. AI 모델이 체계적인 편향(Systematic Biases)을 가질 수 있으며, 이를 통제하거나 증명하기 어려움. 데이터 미저장 정책(Zero-Retention Policy)이 명확하지 않은 경우, 개인정보 유출 위험도 존재하며, 이는 GDPR 규제 준수(GDPR Compliance)와도 직결되는 문제임.
오픈소스 기여 및 개인 프로젝트 점수의 함정
전체 점수의 65%를 차지하는 오픈소스 기여와 개인 프로젝트 항목은 기술적 깊이보다는 양적인 측면을 강조하는 경향이 있음. 이는 GitHub 프로필이 없거나 비공개로 작업하는 우수한 엔지니어들을 불리하게 만들 수 있음. 또한, 가족 부양, 부업 등 현실적인 제약으로 인해 프로젝트에 많은 시간을 투자하기 어려운 지원자들에게 불리하게 작용할 수 있다는 비판이 있음.
채용 시장의 현실과 AI 도구의 역할
일부에서는 지원자 수의 폭증으로 인해 AI 도구가 없으면 채용 파이프라인(Hiring Pipeline) 관리가 불가능하다는 현실적인 의견도 제시됨. 하지만 이러한 도구가 실질적인 역량 검증보다는 단순 필터링에 그치고 있으며, 엔지니어링 팀의 검토 없이 채용팀이 선정한 ATS가 사용되는 경우도 많다고 지적함. 이는 인재 발굴보다는 불운한 지원자를 걸러내는 역할에 그칠 수 있음을 시사함.