하이퍼엑셀, AWS F2 인스턴스로 LLM 추론 비용 70% 절감!
by DD
6개월 전
조회수 44
하이퍼엑셀은 AWS EC2 F2 인스턴스를 활용하여 LPU 기반 LLM 추론 서비스를 구축, 온디맨드(On-demand) 환경을 제공함
기존 물리 서버 기반 PoC 운영의 장비 접근성 및 운영 효율성 문제를 해결하고, PoC 환경 구축 시간 90% 이상 단축
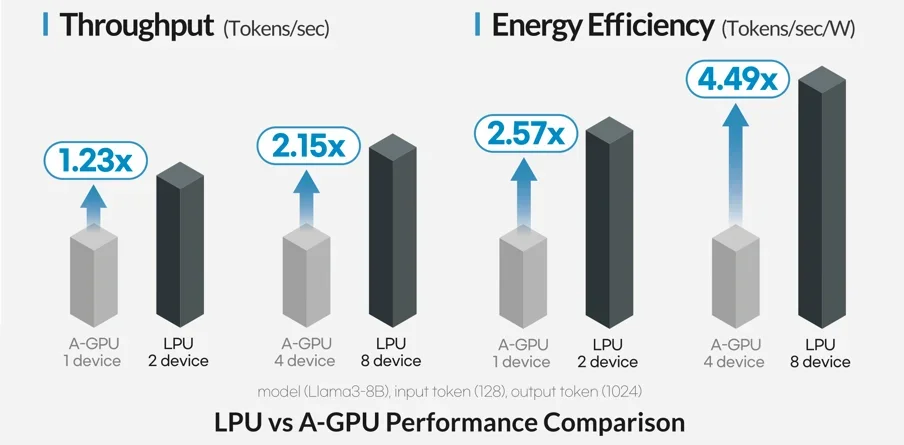
LPU는 A100 GPU 대비 최대 2.15배 높은 추론 처리량, 4.49배 높은 전력 효율을 제공하며, 비용 절감 효과를 보임
AWS Marketplace를 통해 AMI(Amazon Machine Image)를 제공하여 사용자 편의성 및 개발 생산성 향상을 도모함
향후 GPT-OSS 등 신규 LLM 지원 확대 및 MXFP4 양자화 기술 개발을 통해 LPU 기반 LLM 추론 플랫폼으로 발전 계획
F2 인스턴스 기반 LPU 아키텍처
하이퍼엑셀은 AWS EC2 F2 인스턴스의 FPGA(Field-Programmable Gate Array)를 활용하여 LPU(LLM Processing Unit) 아키텍처를 구현했다. F2 인스턴스는 AMD Virtex UltraScale+ HBM VU47P FPGA를 탑재하여, 머신러닝 추론에 적합하다. 하이퍼엑셀은 FPGA Developer AMI와 AWS HDK(Hardware Development Kit)를 사용하여 LPU 아키텍처를 F2 인스턴스에 맞게 재구성했다. 이후, 런타임 툴체인인 HyperDex Toolchain과 AWS SDK를 통합하여 클라우드 환경에서도 온프레미스와 동일한 방식으로 LPU를 제어할 수 있는 환경을 구축했다.
LPU와 GPU의 성능 비교
하이퍼엑셀의 LPU는 A100 GPU 대비 최대 2.15배 높은 추론 처리량과 최대 4.49배 높은 전력 효율을 제공한다. 이러한 성능은 트랜스포머 기반 모델의 연산 특성에 맞춰 설계된 전용 아키텍처 덕분이다. 하이퍼엑셀은 MXFP4 양자화 기술을 개발하여 LPU의 활용성을 더욱 높일 계획이다. 이를 통해 동일한 하드웨어 자원에서 더 큰 모델을 구동하거나 더 높은 추론 처리량을 확보하여 비용 효율성을 극대화할 수 있을 것으로 기대된다.
온프레미스 PoC 환경의 문제점과 클라우드 전환
기존 하이퍼엑셀의 PoC 환경은 물리 서버에 의존하여 장비 접근성 및 운영 효율성에 어려움이 있었다. 고객이 LPU를 사용하려면 LPU가 장착된 서버에 직접 접근해야 했고, 이 과정에서 수작업, 보안 문제, 긴 대기 시간, 환경 불일치 등의 문제가 발생했다. 이러한 문제를 해결하기 위해 하이퍼엑셀은 클라우드 전환을 결정했다. 클라우드 전환을 통해 온디맨드 접근성을 확보하고, PoC 운영 과정에서 발생하는 복잡한 절차와 리소스 낭비를 줄이고자 했다.
AWS Marketplace를 통한 사용자 편의성 증대
하이퍼엑셀은 AWS Marketplace를 통해 LPU 기반 추론 환경을 제공하여 사용자 편의성을 높였다. AMI(Amazon Machine Image)를 통해 고객은 별도의 초기 설정 없이 LPU를 직접 체험할 수 있다. AMI에는 Chat UI, vLLM 플러그인, Docker 실행 환경, HyperDex Toolchain이 사전 설치되어 있다. 사용자는 Marketplace에서 AMI를 선택해 EC2 인스턴스를 실행한 뒤, 웹 기반 Chat UI를 통해 LPU의 추론 결과를 즉시 확인할 수 있다. 모든 구성 요소는 Marketplace를 통해 버전 일관성을 유지하며 중앙에서 관리된다.
LPU-as-a-Service 모델 확장을 위한 기술 로드맵
하이퍼엑셀은 LPU 기반 LLM 추론 플랫폼을 실제 서비스 운영 수준으로 확장하기 위해 기술 로드맵을 수립했다. 주요 기술 방향은 다음과 같다.
GPT-OSS 등 신규 LLM 지원 확대: MoE(Mixture of Experts) 구조를 포함한 GPT-OSS 등 신규 LLM 지원
MXFP4 Quantization 기반 추론 성능 고도화: MXFP4 기반 양자화 기술 개발을 통해 비용 효율성 향상
다양한 서비스 실증 사례 도출: LPU-as-a-Service 형태로 실제 서비스 환경에 LPU 기반 추론 적용
하이퍼엑셀은 AWS의 글로벌 클라우드 인프라를 활용하여 LPU 기반 LLM 추론 환경을 지속적으로 고도화할 계획이다.