GPU 분산 훈련, EFA와 InfiniBand의 선택? DeepEP vs PPLX-kernels
by DD
1개월 전
조회수 14
분산 훈련(Distributed Training)에서 GPU 간 통신 성능이 전체 훈련 효율에 미치는 영향과 데이터 경로(Data Path) 및 제어 경로(Control Path) 관점에서 기술 발전 과정을 설명
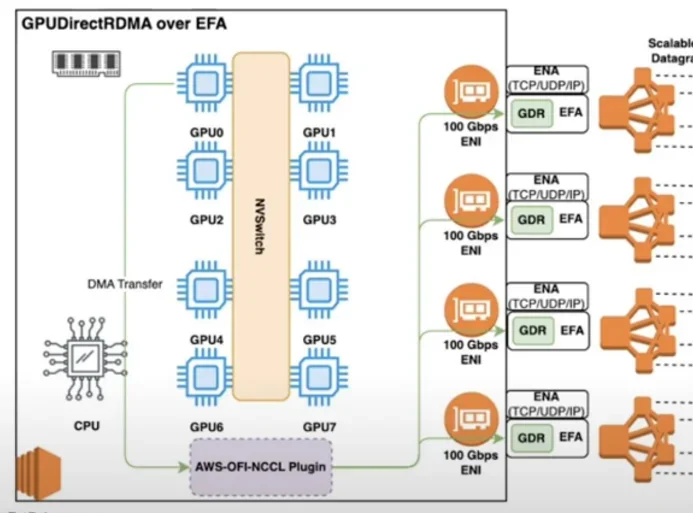
GPUDirect RDMA를 통해 CPU 개입을 줄이고, EFA(Elastic Fabric Adapter)와 결합하여 OS 네트워크 스택까지 우회하는 직접 전송 경로를 구현
DeepEP는 인피니밴드(InfiniBand) 환경에서 IBGDA(InfiniBand GPUDirect Async)를 활용하여 낮은 레이턴시를 달성하지만, AWS EFA 환경에서는 성능 저하 발생
PPLX-kernels는 EFA 환경에 맞춰 GDRCopy를 활용, CPU 프록시(CPU Proxy)와 GPU 간 동기화 오버헤드를 줄여 DeepEP보다 우수한 성능을 보임
하드웨어 스펙보다 네트워크 인터커넥트(Network Interconnect)의 설계 사상을 이해하고, 환경에 맞는 최적화를 적용하는 것이 중요함을 강조
GPU 간 통신 기술 발전 과정: 데이터 경로 vs. 제어 경로
본문은 분산 훈련에서 GPU 간 통신 성능 향상을 위해 CPU 개입을 줄이는 방향으로 기술이 발전해 왔음을 설명한다.
GPUDirect RDMA(GDR): GPU 메모리에서 CPU 메모리를 거치지 않고, NIC(Network Interface Card)이 PCIe를 통해 GPU 메모리에 직접 접근하여 데이터 전송. 를 통해 레이턴시 감소