Elasticsearch, SIMD 최적화로 벡터 검색 성능 4배 향상!
by DD
2개월 전
조회수 8
Elasticsearch는 simdvec을 통해 벡터 검색의 핵심인 거리 계산을 SIMD(Single Instruction Multiple Data) 명령어로 최적화하여 성능을 향상시킴
x86 및 ARM 아키텍처에 특화된 커널을 제공하며, 특히 메모리 레이턴시(Memory Latency)를 줄이기 위해 프리페칭(Prefetching) 및 인터리빙(Interleaving) 기술을 활용함
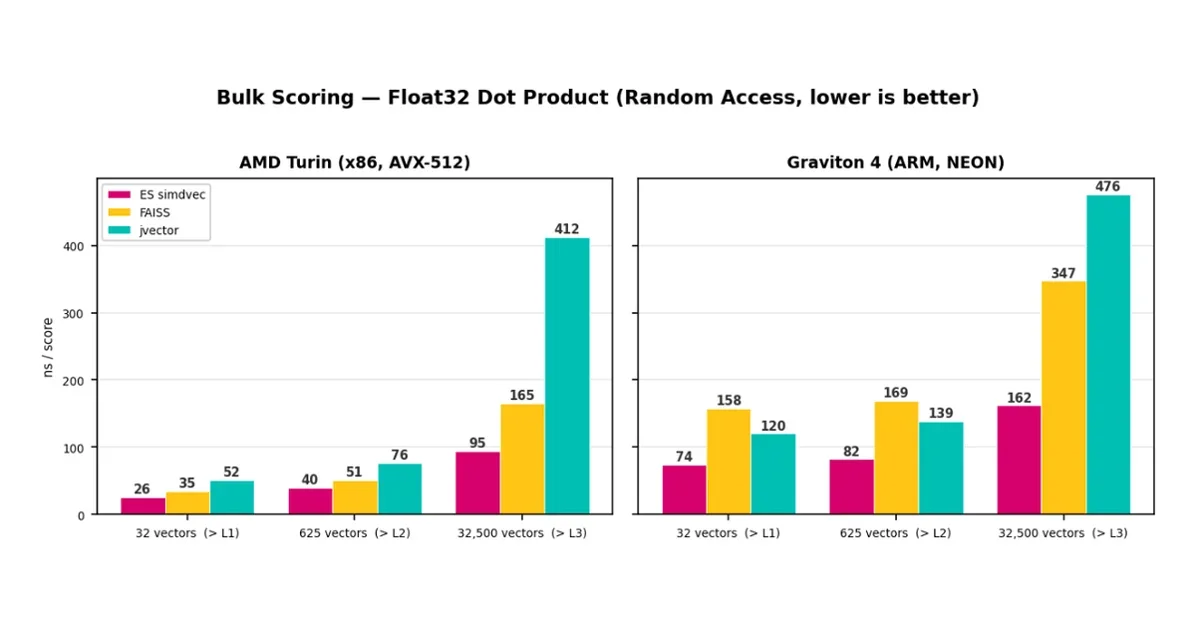
FAISS, jvector 등 경쟁 라이브러리와 비교하여, 데이터가 CPU 캐시를 초과하는 경우 최대 4배의 성능 우위를 보임
댓글에서는 C++로 구현된 simdvec이 Java 기반 라이브러리보다 성능 우위를 보이는 것은 당연하다는 의견이 존재함
simdvec의 핵심 기술: SIMD 최적화
Elasticsearch의 simdvec은 벡터 검색의 핵심 연산인 거리 계산을 SIMD(Single Instruction Multiple Data) 명령어를 사용하여 최적화한다. 특히, AVX-512 및 NEON 커널을 통해 x86 및 ARM 아키텍처에서 각각 특화된 성능을 제공한다. 이러한 SIMD 최적화는 단일 쌍(Single-pair) 연산뿐만 아니라, 대량의 벡터 연산(Bulk Scoring)에서도 성능 향상을 이끌어낸다. 이는 HNSW, IVF, reranking 등 다양한 검색 알고리즘의 성능을 향상시키는 기반이 된다.
메모리 레이턴시(Memory Latency)를 줄이기 위한 전략
simdvec은 메모리 레이턴시(Memory Latency)를 줄이기 위해 x86 및 ARM 아키텍처에 특화된 전략을 사용한다. x86에서는 명시적인 프리페칭(Explicit Prefetching)을 통해 캐시 미스를 줄이고, ARM에서는 인터리빙(Interleaving)을 사용하여 메모리 접근의 병렬성을 높인다. 이러한 전략은 데이터가 CPU 캐시를 초과하는 경우, 즉 대규모 데이터셋에서 simdvec의 성능 우위를 확보하는 핵심 요소로 작용한다.
FAISS, jvector와의 성능 비교
simdvec은 FAISS, jvector와 같은 경쟁 라이브러리와 비교하여, 다양한 데이터 타입 및 쿼리 시나리오에서 우수한 성능을 보였다. 특히, 데이터가 CPU 캐시를 초과하는 경우 최대 4배의 성능 향상을 기록했다. 이러한 성능 차이는 simdvec이 제공하는 벌크 스코어링(Bulk Scoring) 아키텍처와 아키텍처별 최적화된 커널, 그리고 메모리 레이턴시(Memory Latency)를 줄이기 위한 전략에서 기인한다.
아키텍처별 최적화 및 SIMD 명령어 활용
simdvec은 x86 및 ARM 아키텍처에 대해 각각 최적화된 SIMD 커널을 제공한다. x86에서는 AVX-512 명령어를 활용하여 단일 쌍 연산에서 FAISS에 근접하는 성능을 보이며, ARM에서는 NEON 명령어를 사용하여 jvector보다 뛰어난 성능을 보여준다. 이러한 아키텍처별 최적화는 Elasticsearch가 다양한 하드웨어 환경에서 일관된 성능을 유지하는 데 기여하며, 특히 ARM 기반의 Graviton 서버 지원을 통해 클라우드 환경에서의 경쟁력을 강화한다.