C++ 행렬 곱셈, 20배 성능 향상 비법!
by DD
4개월 전
조회수 2
C++에서 행렬 곱셈 성능을 극대화하기 위한 캐시 블로킹(Cache Blocking) 기법을 소개함
SIMD(Single Instruction, Multiple Data) 명령어를 활용하여 데이터 병렬 처리(Data Parallelism) 성능을 향상시키는 방법을 설명함
멀티스레딩(Multithreading)을 통해 CPU 코어 활용률(CPU Core Utilization)을 높여 병렬화 성능을 달성하는 과정을 시연함
다양한 최적화 기법 적용 후 실행 시간(Execution Time) 20배 단축이라는 구체적인 성능 향상 결과를 제시함
행렬 곱셈의 기본 구현과 성능 병목
발표자는 C++에서 행렬 곱셈의 기본적인 3중 루프 구현을 소개하며 시작한다. 이 네이티브 구현은 데이터 지역성(Data Locality) 부족으로 인해 캐시 미스(Cache Miss)를 빈번하게 발생시켜 성능 저하의 주요 원인이 됨을 지적한다. 특히, 행렬 B의 열에 대한 데이터 접근 패턴(Access Pattern)이 비순차적이어서 CPU 캐시 효율성을 저해한다고 설명한다.
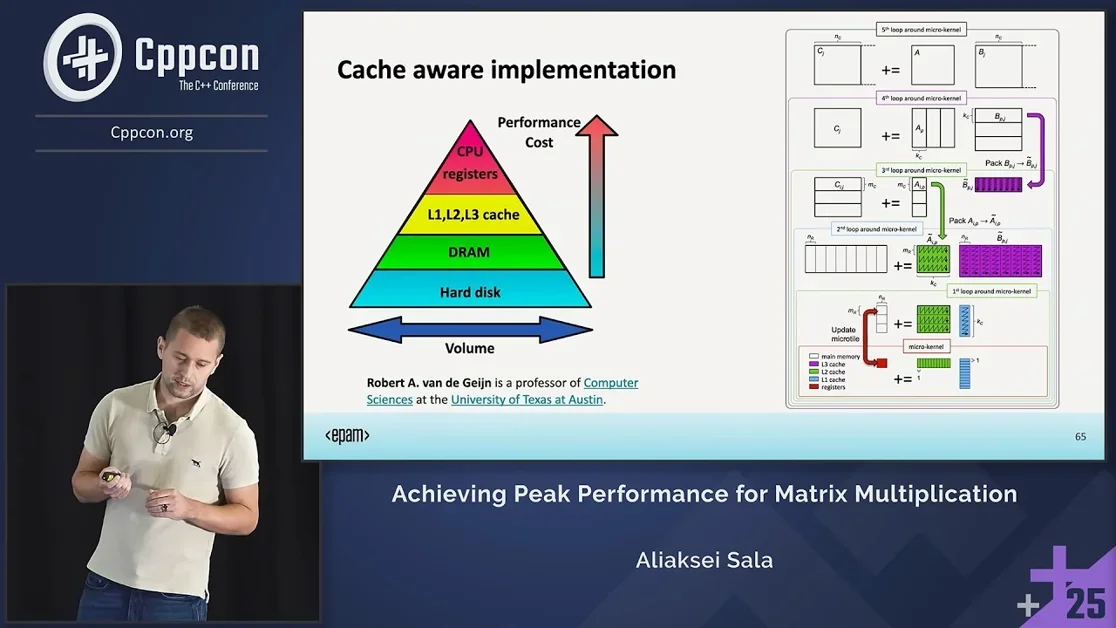
캐시 블로킹(Cache Blocking)을 통한 성능 향상
행렬 곱셈 성능 개선을 위해 발표자는 캐시 블로킹(Cache Blocking) 기법을 적용한다. 이는 행렬을 작은 블록(Block)으로 나누어 처리함으로써 CPU 캐시(L1, L2) 활용률을 극대화하는 방식이다. 블록 크기(Block Size)를 L1 캐시 크기(64KB)에 맞춰 조절하는 것이 핵심이며, 이를 통해 캐시 히트율(Cache Hit Rate)을 높여 메모리 접근 지연 시간(Memory Latency)을 크게 단축시킨다.
루프 순서 변경(Loop Order Permutation)의 효과
네이티브 구현의 비효율적인 데이터 접근 패턴을 개선하기 위해 루프 순서를 변경하는 기법을 설명한다. 기본 IJK 순서에서 IKJ 순서로 변경하면 행렬 A의 데이터 접근이 순차적으로 이루어져 캐시 효율성이 향상된다. 또한, 행렬 B의 데이터 접근 시에도 데이터 스트라이딩(Data Striding)을 최소화하여 메모리 대역폭(Memory Bandwidth) 활용도를 높인다.
SIMD(Single Instruction, Multiple Data) 활용
발표자는 SIMD(Single Instruction, Multiple Data) 명령어를 사용하여 행렬 곱셈의 데이터 병렬성(Data Parallelism)을 극대화하는 방법을 제시한다. AVX2 명령어셋을 활용하여 한 번의 명령으로 여러 데이터 요소를 동시에 처리함으로써 연산 속도를 향상시킨다. 특히, 벡터 레지스터(Vector Register)를 활용하여 행렬 곱셈의 핵심 연산인 스칼라 곱셈과 덧셈을 병렬로 수행하는 FMA(Fused Multiply-Add) 연산의 중요성을 강조한다.
멀티스레딩(Multithreading)을 통한 병렬화
CPU의 멀티코어 활용을 극대화하기 위해 멀티스레딩(Multithreading) 기법을 적용한다. OpenMP 라이브러리를 사용하여 행렬 곱셈 연산을 여러 스레드(Thread)로 분할하고 병렬로 실행한다. 각 스레드는 행렬의 특정 행 또는 블록을 담당하여 계산하며, 스레드 간 데이터 경쟁(Data Race)을 방지하기 위한 동기화 메커니즘(Synchronization Mechanism)의 필요성을 언급한다.
최적화 기법 적용 결과 및 성능 분석
다양한 최적화 기법(캐시 블로킹, SIMD, 멀티스레딩)을 순차적으로 적용한 결과, 최종적으로 행렬 곱셈 성능을 원래 대비 20배 이상 향상시켰다고 발표한다. 각 최적화 단계별 성능 향상률을 비교 분석하며, 특히 SIMD와 캐시 블로킹의 시너지 효과가 성능 향상에 크게 기여했음을 보여준다. 이는 고성능 컴퓨팅(HPC) 환경에서 최적화의 중요성을 다시 한번 강조한다.