EKS Job 워크로드 오토스케일링 도입으로 비용 절감 및 성능 향상!
by DD
3개월 전
조회수 44
Job 워크로드의 특성상 EKS Node Group 오토스케일링 적용에 어려움이 있었으나, Bin-packing과 강제 종료 방지 기술을 통해 문제를 해결
PodAffinity를 활용하여 Job 워크로드 Pod를 동일 Node에 배치함으로써 Bin-packing 효과를 구현하고, Kyverno를 통해 PodAffinity 및 강제 종료 방지 Annotation을 일괄 적용
Production 환경에서 kubelet 과부하, Image Pull 실패, EBS Volume Throttling 등의 문제 발생, maxPods 조정, registryPullQPS/registryBurst 설정, EBS Volume 증설을 통해 해결
오토스케일링 도입 후 Pod Pending 시간 49% 감소, Workflow Pod Running 시간 47% 감소 등 전반적인 성능 개선을 확인
Job 워크로드 오토스케일링의 기술적 난제
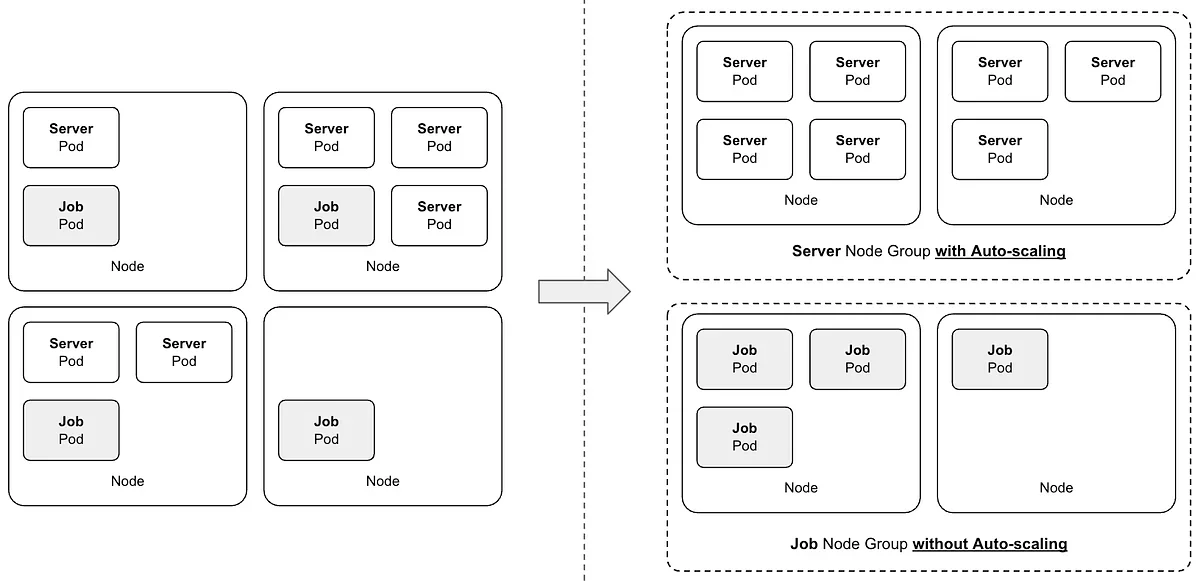
일반적인 Server 워크로드와 달리, Job 워크로드는 실행 시간 예측 불가 및 중단 시 재실행 비용 문제로 인해 오토스케일링 적용에 어려움이 있다. 당근에서는 이러한 제약을 극복하기 위해, Bin-packing과 강제 종료 방지라는 두 가지 핵심 기술을 활용했다.
Bin-packing: PodAffinity를 활용하여 Job 워크로드 Pod를 동일 Node에 배치, Node Scale-in 시 실행 중인 Pod 수를 최소화
강제 종료 방지: Cluster Autoscaler와 Karpenter의 Annotation을 활용하여 실행 중인 Job 워크로드의 강제 중단 방지
결과적으로, Job 워크로드의 특성을 고려한 맞춤형 오토스케일링 전략을 통해 비용 효율성과 안정성을 동시에 확보했다.
PodAffinity를 활용한 Bin-packing 구현
Kubernetes 기본 스케줄러는 Pod를 여러 Node에 분산하는 전략을 사용하므로, Bin-packing을 위해 PodAffinity를 활용했다. PodAffinity는 특정 Pod와 동일한 Node에 다른 Pod를 배치하도록 유도하는 기능이다.
PodAffinity 설정: CronJob YAML 파일을 통해 PodAffinity를 설정, 동일한 Label을 가진 Pod가 많이 실행 중인 Node에 새로운 Pod 배치 유도
Kyverno 활용: Kyverno ClusterPolicy를 통해 Argo Workflow Pod에 PodAffinity 설정 일괄 적용
결과: PodAffinity 적용 전에는 Job 워크로드 Pod가 여러 Node에 분산되었으나, 적용 후에는 특정 Node에 집중되어 Bin-packing 효과를 확인
Production 환경에서의 문제 해결 과정
Alpha 환경에서는 문제없이 동작하던 오토스케일링이 Production 환경에서 예상치 못한 문제들을 발생시켰다. 특히, 특정 시간에 많은 Job 워크로드 Pod가 한꺼번에 생성되면서 Node 부하 집중 문제가 발생했다.
Kubelet 과부하: maxPods 값 조정을 통해 특정 Node에 과도한 Pod가 스케줄링되는 것을 방지
Image Pull 실패: registryPullQPS 및 registryBurst 값 상향 조정을 통해 kubelet의 Image Pull 성능 개선
EBS Volume Throttling: EBS Volume IOPS 및 Throughput 증설을 통해 Container Runtime의 정상 동작 보장
이러한 문제 해결 과정을 통해 Production 환경에서도 안정적인 오토스케일링 운영을 가능하게 했다.
오토스케일링 도입 후 성능 지표 변화
오토스케일링 도입 후, Job 워크로드의 전반적인 성능 개선을 확인했다. 특히, Pod Pending 시간 감소와 Running 시간 단축이 두드러졌다.
Pod Pending 시간: 평균 49% 감소, Image Pull 시간 증가에도 불구하고 Pending 시간 감소
Workflow Pod Running 시간: 47% 감소, job-arm Node Group의 Node 수 증가와 연관
Job Pod Running 시간: 10.56% 증가, maxPods 설정으로 인한 Pod 분산 영향
결과적으로, 오토스케일링 도입을 통해 Node 자원 효율성 향상과 더불어 전반적인 시스템 성능 개선을 달성했다.
오토스케일링 도입 시 고려사항
Job 워크로드 오토스케일링 도입 시, 몇 가지 추가적인 고려 사항이 존재한다. 특히, Cluster Autoscaler와 Multi-AZ 구성의 ASG(Auto Scaling Group)를 함께 사용하는 경우, AZ Rebalancing 기능에 주의해야 한다.
AZ Rebalancing: Scale-in 과정에서 AZ 간 Node 수의 불균형 발생 가능성, Job 워크로드 Pod의 강제 중단 위험
해결 방안: ASG의 AZ Rebalancing 기능 끄기
CNI Plugin: AWS VPC CNI 사용 시, WARM IP 개수 증가 또는 Prefix Mode 도입 검토
이러한 고려 사항들을 통해, 오토스케일링 시스템의 안정적인 운영을 보장할 수 있다.