당근, 200+개 DB 마이그레이션 자동화 플랫폼 구축 성공!
by DD
1개월 전
조회수 150
당근은 200개 이상의 글로벌 DB에서 BigQuery로 데이터를 전송하는 과정에서 소스코드와 설정의 강결합으로 인한 병목 현상 발생
오픈소스 Airbyte 검토했으나 대규모 테이블 처리 시간 문제로 자체 ELT 플랫폼(DT Platform) 구축 결정
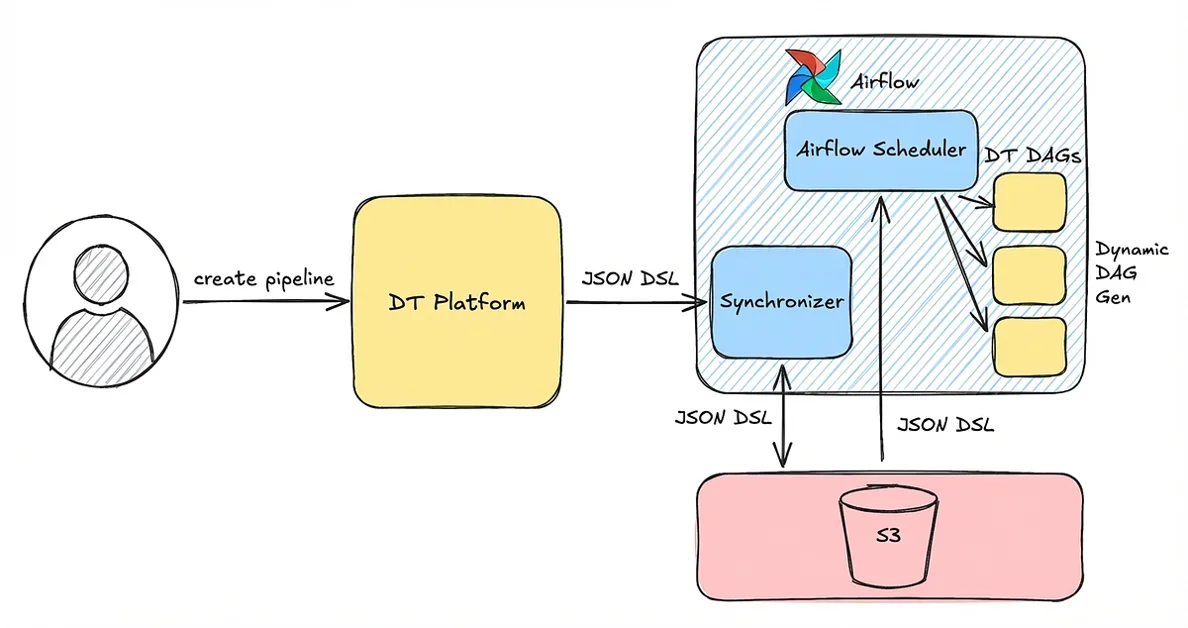
DT Platform은 UI 기반 no-code 데이터 전송으로 서비스 팀의 셀프서비스 운영 지원 및 데이터 가치화 팀의 리뷰 병목 해소
JSON DSL을 통한 파이프라인 정의와 실행 레이어 분리로 코드-설정 강결합 문제 해결
Claude Code 활용 마이그레이션 에이전트와 Notion으로 2주 만에 203개 파이프라인 자동 마이그레이션 완료
기존 ELT의 코드-설정 강결합 문제점 분석
당근의 기존 ELT 파이프라인은 소스코드와 파이프라인 정의가 단일 레포지토리에 강하게 결합되어 있었다. 이로 인해 새로운 테이블 추가나 설정 변경 시 코드 수정 및 PR 리뷰가 필수적이었으며, 이는 데이터 가치화 팀의 리뷰 병목과 서비스 팀의 학습 부담 증가를 야기했다. 각 파이프라인의 상태 추적, 파티션 키 설정, 적재 방식 결정 등 복잡한 정보가 코드베이스에 산재되어 있어 가시성 확보가 어려웠고, 이는 결국 반복적인 설정 리뷰에 팀의 시간을 소모시키는 결과를 초래했다.