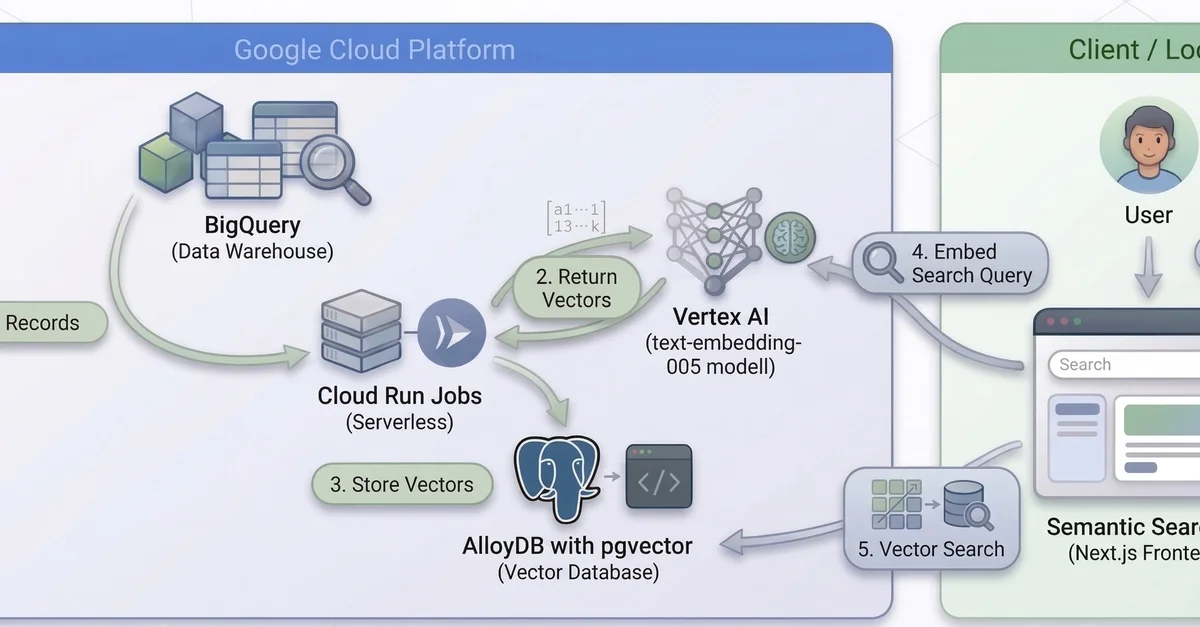
Cloud Run Jobs로 RAG 백엔드 확장성 확보
by DD
3개월 전
조회수 14
RAG 시스템(RAG System)의 데이터 규모가 커짐에 따라 발생하는 성능 병목 현상(Performance Bottleneck)을 해결하기 위한 서버리스(Serverless) 아키텍처를 소개
BigQuery, Cloud Run Jobs, Vertex AI, AlloyDB를 활용하여 병렬 임베딩 생성(Parallel Embedding Generation) 파이프라인 구축
Cloud Run Jobs를 통해 수백 개의 병렬 작업(Parallel Task)을 실행하여 임베딩 생성 속도를 향상시키고, AlloyDB를 활용하여 벡터 검색(Vector Search) 성능 개선
Terraform을 사용하여 인프라 프로비저닝(Infrastructure Provisioning) 자동화 및 AlloyDB Auth Proxy를 통한 안전한 데이터베이스 연결
향후 Zero-Downtime 임베딩 마이그레이션(Embedding Migration) 및 ScaNN 인덱스(ScaNN Index)를 활용한 쿼리 속도 개선 계획 제시
Cloud Run Jobs를 활용한 병렬 임베딩 생성
본문에서는 Cloud Run Jobs를 사용하여 임베딩 생성 작업을 병렬화하여 확장성(Scalability)을 확보하는 방법을 제시한다. 기존의 순차적 처리 방식은 데이터 규모가 커짐에 따라 성능 저하를 겪지만, Cloud Run Jobs를 활용하면 수백 개의 작업을 동시에 실행하여 처리 시간을 단축할 수 있다.
Cloud Run Job 환경 변수(Environment Variables)를 통해 각 작업에 할당된 데이터 샤드(Data Shard)를 계산
Dockerfile을 사용하여 애플리케이션을 컨테이너화하고, deploy.sh 스크립트를 통해 Cloud Run Job으로 배포
google-genai SDK를 사용하여 Vertex AI의 text-embedding-005 모델에 접근하여 임베딩 생성
결과적으로, Cloud Run Jobs는 서버리스(Serverless) 환경에서 대규모 데이터 처리를 위한 효과적인 솔루션을 제공한다.
AlloyDB를 활용한 고성능 벡터 검색
글에서는 AlloyDB for PostgreSQL을 사용하여 벡터 데이터를 저장하고 검색하는 방법을 설명한다. AlloyDB는 pgvector 확장 기능을 내장하여 고성능 벡터 검색(High-Performance Vector Search)을 지원하며, 대규모 데이터셋에서도 빠른 쿼리 속도를 보장한다.
pgvector 확장(pgvector Extension)을 통해 벡터 데이터 타입(Vector Data Type) 지원
ScaNN 인덱스(ScaNN Index)를 생성하여 쿼리 속도(Query Speed)를 더욱 향상시킬 수 있음 (향후 구현 예정)
AlloyDB Auth Proxy를 사용하여 로컬 개발 환경(Local Development Environment)에서 안전하게 데이터베이스에 연결
AlloyDB는 RAG 시스템의 핵심 요소인 벡터 검색(Vector Search)의 성능을 극대화하여 사용자 경험을 향상시킨다.
Terraform을 이용한 인프라 자동화
본문에서는 Terraform을 사용하여 AlloyDB 클러스터, Artifact Registry, Cloud Run Job 등 필요한 인프라를 프로비저닝(Provisioning)하는 방법을 소개한다. Terraform을 사용하면 인프라 구축 및 관리를 자동화하여 반복적인 작업(Repetitive Task)을 줄이고, 인프라 구성(Infrastructure Configuration)의 일관성을 유지할 수 있다.
Terraform init, plan, apply 명령어를 사용하여 인프라 배포
-var 옵션을 통해 프로젝트 ID(Project ID) 및 데이터베이스 비밀번호(Database Password) 설정
tfplan 파일을 사용하여 배포 계획(Deployment Plan)을 저장하고, 배포 과정의 안정성 확보
Terraform을 활용하면 인프라 구축 과정을 자동화하여 개발 생산성을 향상시키고, IaC(Infrastructure as Code)를 통해 인프라 관리 효율성을 높일 수 있다.
Vertex AI text-embedding-005 모델 활용
글에서는 Vertex AI의 text-embedding-005 모델을 사용하여 텍스트 임베딩(Text Embedding)을 생성하는 방법을 설명한다. text-embedding-005 모델은 최신 기술을 기반으로 하며, RAG 시스템에서 검색 정확도(Search Accuracy)를 향상시키는 데 기여한다.
google-genai SDK를 사용하여 Vertex AI 모델에 접근
EmbedContentConfig를 통해 작업 유형(Task Type) 및 출력 차원(Output Dimensionality) 설정
text-embedding-005 모델은 768차원의 임베딩 벡터(Embedding Vector)를 생성
Vertex AI를 활용하면 별도의 모델 학습 없이도 고품질의 임베딩을 생성할 수 있으며, RAG 시스템의 성능(Performance)을 향상시킬 수 있다.
RAG 시스템의 테스트 및 모니터링 전략
본문에서는 RAG 시스템의 테스트 및 모니터링 전략에 대한 간략한 내용을 언급한다. 특히, Next.js 기반의 Semantic Search UI를 통해 임베딩 결과를 시각적으로 확인하고, 시스템의 동작을 검증한다.
Semantic Search UI를 로컬 환경에서 실행하여 자연어 쿼리(Natural Language Query) 테스트
.env 파일을 통해 Google Cloud 프로젝트 ID 및 AlloyDB DB_PASSWORD 설정
ScaNN 인덱스(ScaNN Index)를 생성하여 쿼리 속도(Query Speed) 개선 (향후 구현 예정)
결과적으로, RAG 시스템의 테스트(Testing) 및 모니터링(Monitoring)은 시스템의 안정성과 성능을 보장하는 데 필수적이며, 지속적인 개선을 위한 기반을 마련한다.