G5/G6 인스턴스 + Tensor Parallelism = LLM 비용 절감!
by DD
1개월 전
조회수 8
대형 LLM(Large Language Model)의 GPU 메모리 요구량 증가로 인해 고가 GPU 확보의 어려움이 발생함
Tensor Parallelism(TP) 기술을 활용하여, G5/G6 인스턴스(NVIDIA A10G/L4 GPU)와 같이 상대적으로 작은 GPU에서도 LLM 서빙 가능함을 입증
vLLM을 사용하여 TP=4 구성 시, 토큰 생성 속도(TPOT)가 최대 65.7% 개선되었으며, 동시 사용자 증가 시에도 높은 처리량 유지
G5/G6 인스턴스에서 TP를 적용하면, H100/H200 GPU 확보 지연 없이 LLM 서비스를 시작할 수 있으며, 필요에 따라 상위 인스턴스로 확장 가능
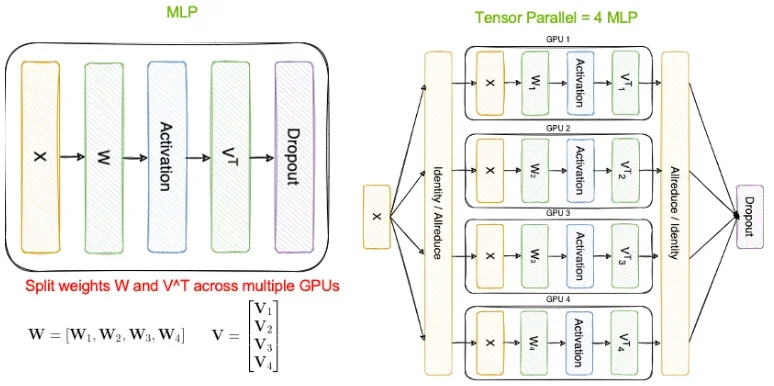
Tensor Parallelism(TP)의 작동 원리
본문에 따르면 텐서 병렬 처리(Tensor Parallelism)는 모델의 Transformer Tensor 연산을 여러 GPU에 분할하는 기술이다. 각 GPU는 모델 파라미터의 일부만 보유하며, 레이어마다 All-Reduce 통신(All-Reduce Communication)을 통해 중간 결과를 동기화한다.
MLP(Multi-Layer Perceptron) Operation: W와 VT 벡터를 분할하여 각 GPU에서 병렬 처리
vLLM의 PagedAttention과 Continuous Batching: 대규모 언어 모델(LLM)의 고속·고효율 서빙을 지원
TP=4 구성: 64GB 모델을 4개의 GPU에 분산 배치하여, GPU당 16GB의 모델 파라미터 적재
이러한 방식을 통해, 작은 GPU에서도 대형 모델을 서빙할 수 있으며, 응답 속도 향상까지 기대할 수 있다.
G5/G6 인스턴스에서의 성능 벤치마크
글에서는 G5 인스턴스(A10G 4장)를 사용하여 Qwen3-8B 모델에 대한 TP=1, 2, 4 구성별 성능을 측정했다. 테스트는 vLLM 추론 엔진과 OpenAI API 호환 서버를 기반으로 진행되었으며, 비동기 프로그래밍(Asynchronous Programming)과 SSE(Server-Sent Events) 기반 스트리밍 방식을 활용했다.
토큰 생성 속도(TPOT): TP=4 구성 시, 모든 동시성 수준에서 52~66% 개선
전체 처리량(Aggregate Throughput): TP=4 구성 시, C=16에서 TP=1 대비 2.1배 향상
응답 시간: TP=4 구성 시, 16명 동시 사용 환경에서 52% 단축
이러한 결과는 다중 GPU 환경(Multi-GPU Environment)이 동시 사용자 증가에 따른 성능 저하를 완화하고, 사용자 경험을 개선하는 데 효과적임을 보여준다.
TP vs 수평 확장(Horizontal Scaling) 비교
본문은 TP와 수평 확장의 장단점을 비교 분석하며, 워크로드 특성에 따른 적합한 전략을 제시한다. TP는 단일 서버에서 여러 GPU를 활용하여 개별 응답 속도(Individual Response Speed)를 향상시키는 데 유리하며, 수평 확장은 여러 서버를 사용하여 전체 처리량(Total Throughput)을 극대화하는 데 적합하다.
대형 모델 서빙: TP는 24GB GPU로 70B+ 모델 서빙 가능, 수평 확장은 단일 GPU에 모델 적재 필요
적합 서비스: TP는 대화형 AI, 실시간 보조에 적합, 수평 확장은 배치 처리, API 서비스에 적합
아키텍처 복잡도: TP는 단일 서버, 수평 확장은 Load Balancer 및 복수 서버 관리 필요
결론적으로, 모델 크기와 서비스 요구 사항을 고려하여 적절한 아키텍처를 선택해야 한다.
G5/G6 인스턴스 활용을 위한 실전 가이드
글에서는 모델 크기별 G5/G6 서빙 가이드와 함께, 실제 운영 환경에서의 고려 사항을 제시한다. 특히, Auto Scaling 환경(Auto Scaling Environment)에서의 서버 시작 시간 증가를 고려하여 Warm Pool이나 사전 프로비저닝을 활용할 것을 권장한다.
모델 크기별 TP 구성: 8B 모델은 TP=1, 2, 4 구성, 32B 모델은 TP=4 구성
양자화(Quantization) 활용: AWQ, GPTQ 등의 INT4/INT8 양자화를 적용하여 GPU 메모리 절감
벤치마크 필수: 실제 서비스 적용 전, 자체 모델과 워크로드로 벤치마크 수행 권장
이러한 가이드를 통해, G5/G6 인스턴스를 활용한 LLM 서빙 환경을 효율적으로 구축할 수 있다.
다중 GPU 환경의 이점 심층 분석
본문은 다중 GPU 환경이 동시 사용 환경에서 가지는 이점을 심층적으로 분석한다. KV Cache 메모리 분산(KV Cache Memory Distribution)을 통해 단일 GPU 메모리 한계를 극복하고, 연산 병렬화(Operation Parallelization)를 통해 토큰 생성 속도를 향상시킨다.
Throughput Scaling: C=16에서 TP=4는 TP=1 대비 2.1배 높은 절대 처리량 제공
16명 동시 사용 시: TP=4는 TP=1 대비 전체 처리량 2.1배 향상, 응답 시간 52% 단축, 개인 체감 속도 2.1배 향상
GPU당 처리량 효율: 다수의 GPU를 사용할수록 GPU당 효율 감소, PCIe 환경의 All-Reduce 통신 오버헤드 때문
결과적으로, 다중 GPU 환경은 확장성(Scalability)과 비용 효율성(Cost Efficiency)을 동시에 고려할 수 있는 실용적인 선택지임을 강조한다.