나만의 LLM 위키로 AI 활용 생산성 UP!
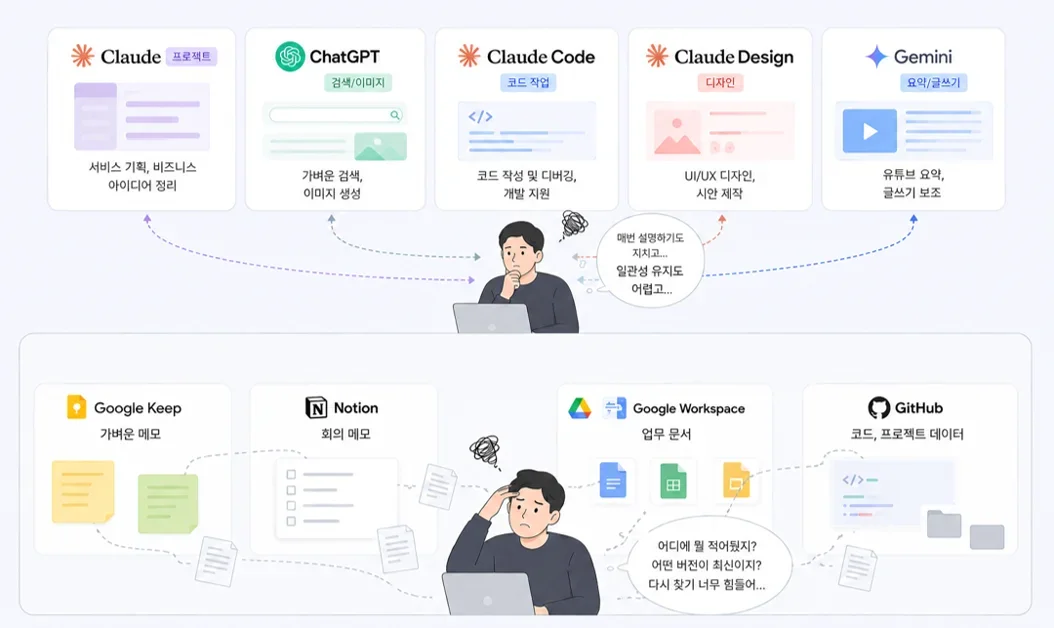
여러 AI 도구 사용 시 발생하는 컨텍스트 전달의 번거로움을 해소하기 위해 개인 정보 통합 시스템 구축 필요성 제기
옵시디언(Obsidian), 깃허브(GitHub), 클로드 코드(Claude Code)를 활용하여 개인 맞춤형 LLM 위키 구축 시작
분산된 개인 데이터를 통합하고 AI가 활용 가능한 형태로 만들어 AI 활용 생산성 극대화 목표
LLM 위키 구축 과정에서 얻은 데이터 통합, 자동화, 보안 및 협업 관련 인사이트 공유
개인 컨텍스트 통합을 위한 LLM 위키 아키텍처
본 글에서는 여러 AI 도구 사용 시 발생하는 컨텍스트 전달의 비효율성을 해결하기 위해 옵시디언(Obsidian)을 중심으로 개인 지식 베이스인 LLM 위키를 구축하는 과정을 설명합니다. 흩어진 개인 데이터(흩어진 정보)를 옵시디언 볼트(Vault)로 통합하고, 깃허브(GitHub) Private Repo를 통해 안정적인 동기화(Stable Synchronization)를 확보하며, 클로드 코드(Claude Code) CLI를 활용하여 데이터 수집 및 정리 자동화(Data Collection & Organization Automation)를 구현하는 것이 핵심 아키텍처입니다. 이는 AI 에이전트가 '나 자신'에 대한 온전한 맥락을 파악하고 활용하는 데 필수적인 기반을 제공합니다.
옵시디언(Obsidian) 기반 데이터 수집 및 동기화 전략
LLM 위키 구축을 위해 옵시디언(Obsidian)을 선택한 이유는 빠른 속도, 안정적인 동기화, 그리고 워크플로우 적합성 때문입니다. 웹 정보는 옵시디언 웹 클리퍼(Obsidian Web Clipper)와 모바일 공유 기능을 통해, 파일은 임시 폴더 저장 후 클로드 코드(Claude Code)로 일괄 정리하는 통합된 자료 수집 경로(Unified Data Collection Path)를 구축했습니다. 기기 간 동기화는 깃허브 Private Repo를 활용하며, 모바일 환경에서는 Working Copy 앱을 통해 Git 저장소 연동(Git Repository Integration)을 구현했습니다. 이는 데이터의 일관성(Data Consistency)을 유지하고 여러 기기에서 접근성을 높이는 데 중요합니다.
클로드 코드(Claude Code)를 활용한 LLM 위키 자동화
LLM 위키의 핵심은 AI가 위키를 작성하고 관리하는 데 있습니다. 이를 위해 클로드 코드(Claude Code) CLI를 사용하여 자료 인입(/ingest), 위키 상태 점검(/lint), 그리고 위키 기반 질의(/query) 기능을 자동화했습니다. 특히, CLAUDE.md 파일을 시스템 컨텍스트로 주입하여 AI 작업의 일관성을 확보하고, 스케줄 기능을 활용해 매일 위키 정합성 검사(Daily Wiki Integrity Check)를 수행합니다. 또한, 옵시디언 스킬(Obsidian Skills)을 설치하여 옵시디언 특화 문법 처리 및 복잡한 작업을 지원합니다.
개인 데이터 보안 및 민감 정보 처리 방안
LLM 위키는 개인의 민감 정보를 포함할 수 있으므로 강력한 보안 조치(Robust Security Measures)가 필수적입니다. 클로드 코드(Claude Code)의 정규식(Regex) 기반 민감 정보 마스킹(Sensitive Information Masking) 기능과 /lint 스킬을 활용하여 비밀번호, 카드번호 등을 1차적으로 처리합니다. 하지만 완벽하지 않으므로 주기적인 검토가 필요하며, 깃허브 Private Repo 사용 시에도 2단계 인증(Two-Factor Authentication) 및 토큰 회전 등 추가적인 보안 설정이 권장됩니다. 이는 데이터 유출 위험(Data Leakage Risk)을 최소화하기 위함입니다.
LLM 위키 구축의 한계점 및 개선 방향
LLM 위키 구축 과정에서 이미지 기반 자료의 텍스트 인식 오류, 민감 정보 처리의 불완전성, 깃허브 계정 해킹 시 전체 데이터 노출 위험(Full Data Exposure Risk) 등의 한계점이 드러났습니다. 또한, 개인 위키와 팀 공유용 위키 간의 정보 중복 관리(Duplicate Information Management) 문제도 발생했습니다. 이러한 문제 해결을 위해 향후 AI의 이미지 텍스트 인식 정확도 향상, 보다 정교한 민감 정보 필터링, 그리고 협업 시나리오에 맞는 컨텍스트 공유 전략(Context Sharing Strategy) 마련이 필요합니다.