딥러닝 모델의 핵심, Attention 메커니즘 완벽 분석!
by DD
10개월 전
조회수 18
Attention 기법은 딥러닝 모델이 입력 데이터의 중요 정보에 집중하도록 돕는다.
Self-Attention 기반의 Transformer 모델은 병렬 처리를 가능하게 함
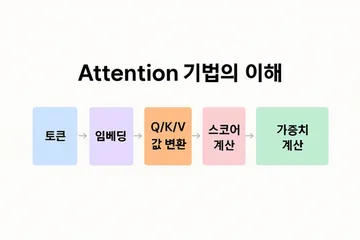
Q/K/V 기반의 가중치 계산을 통해 문맥 이해 능력을 향상시킨다.
Attention 작동 원리: Q, K, V
Attention은 Q(Query), K(Key), V(Value)를 활용하여 입력 시퀀스 내 중요도를 계산한다. 구체적으로, Q는 질문, K는 단서, V는 실제 정보를 의미한다. 따라서, Q와 K 간의 유사도를 통해 가중치를 계산하고, 이를 V에 적용하여 최종 출력을 생성한다.
Self-Attention과 Scaled Dot-Product Attention
Self-Attention은 입력 시퀀스 내 각 단어 간의 관계를 파악하는 데 사용된다. Scaled Dot-Product Attention은 Q와 K의 내적을 통해 유사도를 계산하고, 이를 스케일링하여 Softmax 함수를 적용한다. 따라서, Softmax를 통해 얻은 가중치를 V에 곱하여 최종 출력 벡터를 생성한다.
PyTorch와 TensorFlow 예제 분석
본문에서는 PyTorch와 TensorFlow를 사용한 Attention 구현 예제를 제공한다. 구체적으로, 임베딩 레이어를 통해 토큰을 벡터로 변환하고, Q/K/V를 계산한다. 따라서, Scaled Dot-Product Attention 함수를 통해 가중치를 계산하고, 최종 출력을 얻는다. 코드 예제를 통해 실제 구현을 이해할 수 있다.