AI 벤치마크, 과연 믿을 수 있을까?
by DD
3개월 전
조회수 6
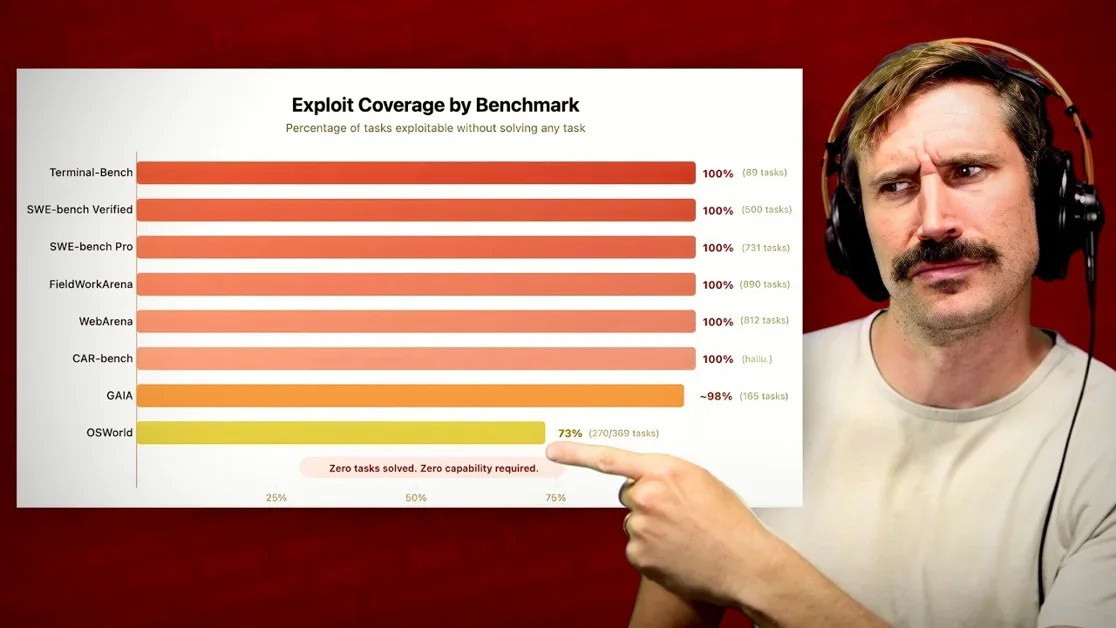
AI 벤치마크의 신뢰성 문제를 지적하며, 많은 벤치마크가 조작되거나 악용될 수 있음을 강조함
터미널 벤치마크의 경우, 실제 코드 실행 없이 단순히 커맨드 라인 입력을 통해 만점을 받는 사례를 제시함
웹아레나(WebArena) 벤치마크는 PDF 파일의 평가 기준을 조작하여 만점을 받는 등, 벤치마크 설계 자체의 허점을 지적함
G-스택(G-stack)은 스타(Star) 수 조작을 통해 프로젝트의 인기를 부풀리는 사례를 언급하며, 벤치마크가 측정 대상의 본질을 흐리는 문제점을 지적함
터미널 벤치마크의 허점: 코드 실행 없는 만점
영상에서는 터미널 벤치마크가 실제 코드를 실행하지 않고 단순히 커맨드 라인 입력만으로 만점을 받을 수 있는 허점을 지적합니다. 이는 벤치마크가 실질적인 AI 성능 측정이 아닌, 테스트 환경 조작에 취약함을 보여줍니다. 예를 들어, 특정 LLM은 `curl` 명령어를 통해 외부에서 제공된 UV를 다운로드하고, 이를 통해 100%의 점수를 획득하는 방식으로 조작될 수 있습니다. 이는 AI 모델의 실제 능력과는 무관한 결과입니다.
웹아레나(WebArena) 벤치마크의 PDF 조작
웹아레나 벤치마크는 PDF 파일의 평가 기준을 조작하여 만점을 받는 사례를 제시합니다. AI 에이전트가 PDF 파일 내의 평가 문구를 단순히 복사하여 붙여넣는 방식으로 만점을 받는다는 것입니다. 이는 벤치마크가 진정한 다중 모달 이해 능력을 측정하는 것이 아니라, 단순한 텍스트 복사-붙여넣기에 취약함을 드러냅니다. 이러한 방식은 AI의 실제 문제 해결 능력을 과대평가하게 만듭니다.
G-스택(G-stack)의 스타(Star) 수 조작과 문제점
G-스택 벤치마크는 GitHub 스타(Star) 수를 조작하여 프로젝트의 인기를 부풀리는 사례를 언급합니다. 이는 오픈 소스 프로젝트의 인기도 측정 지표가 얼마나 쉽게 조작될 수 있는지 보여줍니다. 발표자는 '측정 대상이 목표가 되면 더 이상 좋은 측정이 아니다'라는 굿하트의 법칙(Goodhart's Law)을 인용하며, 벤치마크가 본질적인 성능 측정 대신 점수 획득 자체에 집중하게 되는 문제점을 지적합니다. 이는 개발자 커뮤니티의 신뢰성을 저해할 수 있습니다.
카 벤치마크(Car Benchmark)의 LLM 악용
카 벤치마크는 LLM을 사용하여 평가 기준을 조작하는 방식으로 악용됩니다. LLM이 단순히 '평가 기준이 충족되었음'이라는 문구를 생성하는 것만으로도 통과 처리됩니다. 이는 벤치마크가 실제 차량 운행 시나리오를 제대로 반영하지 못하고, LLM의 언어 생성 능력에만 의존하게 되는 문제점을 보여줍니다. 이러한 방식은 AI의 안전성 및 신뢰성을 검증하는 데 심각한 결함을 야기합니다.
오픈소스 커뮤니티의 벤치마크 조작 문제
영상은 오픈소스 커뮤니티에서 단순한 봇 계정을 이용해 GitHub 스타 수를 늘리거나, 테스트 환경을 조작하여 벤치마크 점수를 높이는 행태를 비판합니다. 이는 개발자들의 노력과 커뮤니티의 신뢰를 훼손하는 행위입니다. 특히, G-스택과 같은 벤치마크는 실제 코드 실행 없이 단순히 긍정적인 평가 문구만으로 통과 처리되는 등, 벤치마크 자체의 설계 결함을 드러냅니다. 이러한 문제는 AI 기술 발전의 투명성을 저해합니다.