Word2Vec으로 연관 키워드 추천 시스템 구축: 초기화 문제 해결 노하우
연관 키워드 추천 시스템 구축을 위해 사용자의 검색 로그를 분석하고, 동시 검색 패턴과 지역적 & 맥락적 타당성을 핵심 조건으로 정의함
Word2Vec 모델을 선정하여, 순서성, 키워드 간 관계, 사전적 의미가 아닌 행동 기반 연관성을 고려한 모델링을 수행함
모델 학습 과정에서 발생하는 초기화 문제(Initialization Problem)를 해결하기 위해, Co-occurrence Filtering을 활용한 하이브리드 파이프라인을 설계함
그 결과, 롱테일(Long-tail) 영역의 세부 지역 및 명소 관련 키워드 추천 정확도를 향상시킴
Word2Vec 모델 선정 배경
본문에서는 연관 키워드 추천을 위해 Word2Vec 모델을 선택한 배경을 설명한다. 순서성(Sequence), 키워드 간의 동적 관계(Dynamic Relationship), 그리고 사전적 의미(Lexical Similarity)보다는 사용자의 행동 기반 연관성(Behavior-based Association)을 중시했기 때문이다. 특히, 여행 및 숙소 도메인의 특성을 고려하여, 고정된 벡터를 통해 고유명사 간의 전역적 관계를 파악하는 Word2Vec이 적합하다고 판단했다.
데이터 전처리 및 모델 학습 과정
저자는 검색 로그 데이터의 Synonyms(동의어) 문제를 해결하기 위해 텍스트 정규화 과정을 거쳤다. 이는 동일한 의미를 가진 검색어들이 다양한 형태로 파편화되어 입력되는 문제를 해결하기 위함이다. 구체적으로, 사내 질의어 분류기와 사전 데이터를 활용하여 텍스트를 정규화하고, 정규화된 데이터를 바탕으로 Word2Vec 모델을 학습시켰다. 그 결과, 코사인 유사도(Cosine Similarity)를 기반으로 각 키워드별 연관 추천 목록을 생성했다.
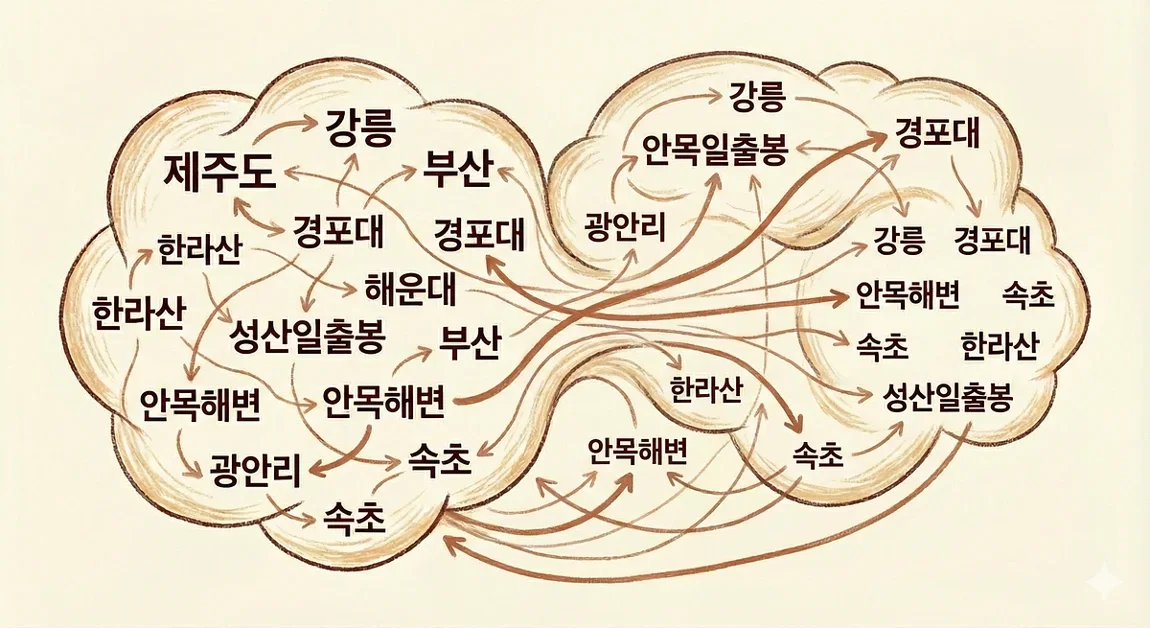
초기화 문제(Initialization Problem)와 해결 방법
Word2Vec 모델 학습 초기에 발생하는 초기화 문제(Initialization Problem)는 모델이 초기화된 랜덤 위치 근처에 머무르는 현상을 발생시킨다. 이를 해결하기 위해, 저자는 Co-occurrence Filtering을 활용한 하이브리드 파이프라인을 설계했다. 먼저 Word2Vec 모델을 통해 폭넓게 연관 키워드 후보를 생성하고, 후보 키워드들이 실제 로그상에서 동시 출현했는지 통계적으로 검증하여 초기화 문제로 인한 노이즈를 제거했다.
하이브리드 파이프라인의 효과
Co-occurrence Filtering을 적용한 결과, 초기화 문제로 발생했던 노이즈가 제거되고 지역적 & 맥락적 타당성을 갖춘 키워드들이 상위로 랭크되었다. 이는 롱테일(Long-tail) 영역의 세부 지역이나 명소 관련 키워드 추천 정확도를 향상시키는 데 기여했다. 본 시스템은 사용자의 실제 탐색 맥락을 보존하면서도 시스템의 운영 효율성을 동시에 확보하는 결과를 달성했다는 점에서 의의가 있다.