RAG 탈출! 가상 파일 시스템으로 AI 문서 검색 혁신
by DD
3개월 전
조회수 18
기존 RAG 시스템의 단점(Limitations)을 보완하고자, 가상 파일 시스템(Virtual Filesystem)을 구축하여 문서 검색 성능을 향상시킴
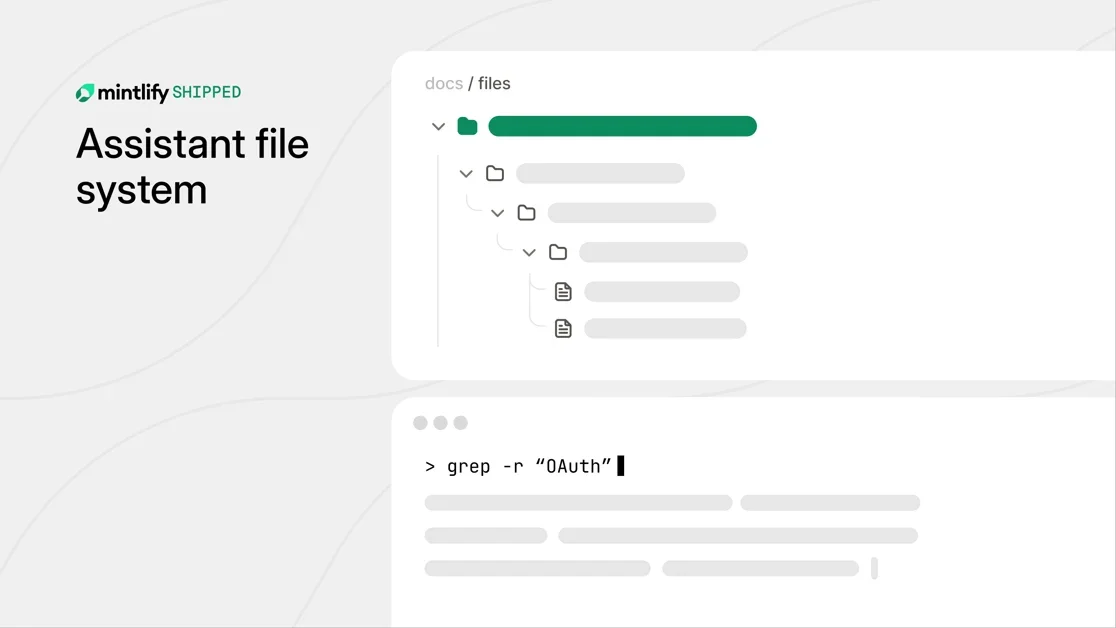
ChromaDB를 기반으로, grep, cat, ls, find 등의 유닉스 명령어를 지원하는 가상 파일 시스템인 ChromaFs를 개발
샌드박스(Sandbox) 기반 RAG 시스템 대비 세션 생성 시간(Session Creation Time)을 획기적으로 단축하고, 비용 절감(Cost Reduction) 효과를 달성
파일 시스템 기반 검색(Filesystem-based Search)의 장점과 데이터베이스(Database) 활용의 효율성에 대한 커뮤니티 논의가 활발하게 진행됨
RAG 시스템의 한계와 가상 파일 시스템 도입 배경
기존 RAG 시스템은 쿼리와 정확히 일치하는 텍스트 청크(Chunk)만 검색 가능하여, 여러 페이지에 걸쳐 있거나 정확한 구문이 필요한 경우 한계가 있었다. 이에 저자는 코드베이스(Codebase) 탐색과 유사한 방식으로 문서를 탐색할 수 있도록 가상 파일 시스템을 구축했다. 특히, grep, cat, ls, find와 같은 유닉스 명령어를 활용하여 에이전트(Agent)가 문서를 탐색하도록 설계했다. 이는 기존 샌드박스(Sandbox) 기반 RAG 시스템의 높은 지연 시간(High Latency)과 인프라 비용(Infrastructure Cost) 문제를 해결하기 위한 시도이다.