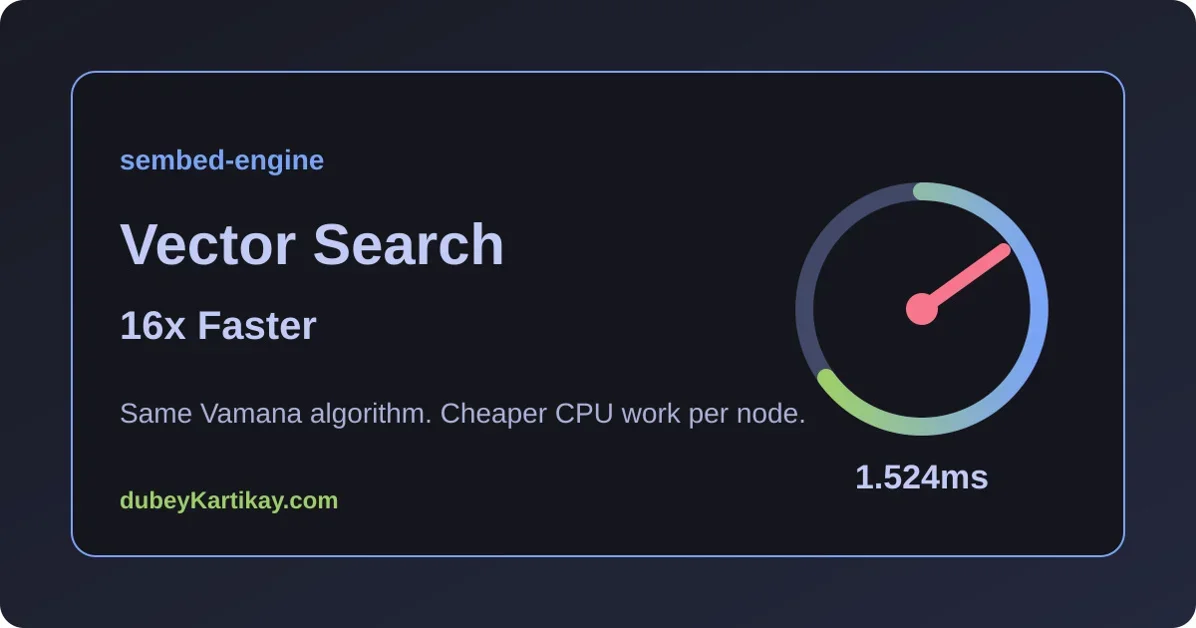
C++ 벡터 검색 엔진, 데이터 레이아웃 변경으로 16배 성능 향상!
by DD
2개월 전
조회수 20
C++ 기반 벡터 검색 엔진의 성능 개선을 위해 데이터 레이아웃(Data Layout)을 변경하여 획기적인 성능 향상을 달성
기존 객체 기반 구조에서 플랫 배열(Flat Array)로 변경하여 캐시 미스(Cache Miss)를 줄이고 SIMD(Single Instruction, Multiple Data) 연산을 활용
제곱 거리(Squared Distance) 사용 및 정렬 시 거리 재계산 방지를 통해 불필요한 연산 제거
알고리즘 변경 없이 쿼리 지연 시간(Query Latency)을 최대 16.5배 단축, 빌드 시간(Build Time) 단축 및 리콜(Recall) 유지
데이터 레이아웃 변경을 통한 성능 개선
저자는 기존의 객체 기반 데이터 레이아웃(Object-heavy Data Layout)에서 플랫 배열(Flat Array) 기반으로 변경하여 성능을 개선했다. 기존에는 각 레코드가 벡터 객체에 대한 포인터를 가지고 있어, 쿼리 처리 시 포인터 추적(Pointer Chasing) 및 가상 함수 호출(Virtual Method Call)로 인해 성능 저하가 발생했다. 특히, 캐시 미스(Cache Miss)가 빈번하게 발생하여 CPU의 효율성을 떨어뜨렸다. 변경 후, 연속된 메모리 공간에 벡터 데이터를 저장하여 SIMD(Single Instruction, Multiple Data) 연산을 가능하게 했다.