LLM 모델 압축 기술 'Unweight'로 GPU 메모리 효율 극대화!
by DD
3개월 전
조회수 18
LLM 추론(Inference) 성능 향상을 위해 모델 가중치(Model Weights) 압축 기술인 Unweight를 개발
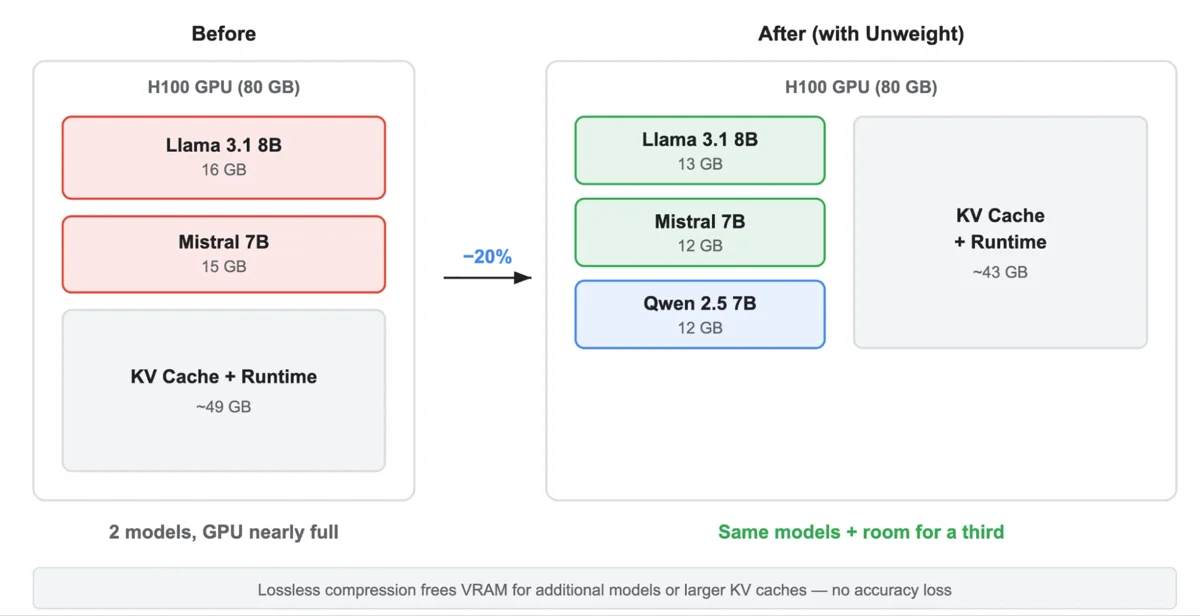
손실 없는(Lossless) 압축 방식을 통해 모델의 정확도를 유지하며, H100 GPU 환경에서 최적화
MLP 가중치(MLP Weights) 압축을 통해 모델 크기를 최대 22%까지 줄이고, VRAM 사용량(VRAM Usage) 3GB 절감 효과
4가지 실행 파이프라인(Execution Pipelines)과 자동 튜닝(Autotuning)을 통해 다양한 워크로드(Workload)에 유연하게 대응
오픈 소스(Open Source)를 통해 기술 공유 및 생태계 기여, 향후 Down Projection 압축 및 커널 최적화(Kernel Optimization) 계획
Unweight의 핵심 원리: 손실 없는 가중치 압축
Unweight는 LLM 모델의 BF16 가중치(Weights)에서 지수(Exponent) 값의 중복성을 활용하여 손실 없이 압축한다.
Huffman 코딩(Huffman Coding): 가장 빈번한 지수 값에 짧은 코드를 할당하여 지수 압축(Exponent Compression) 30% 달성
MLP 가중치(MLP Weights) 선택적 압축: 게이트(Gate), 업(Up), 다운(Down) 프로젝션(Projection)에 적용하여 전체 모델 크기(Model Size) 15~22% 감소
예외 처리(Exception Handling): 희귀한 지수 값을 가진 가중치는 압축하지 않고, 행 단위(Row-wise)로 저장하여 성능 저하 방지
이러한 방식을 통해 모델의 정확성을 유지하면서 메모리 사용량을 줄이는 데 성공했다.
H100 GPU 환경에서의 최적화 전략
Unweight는 H100 GPU의 메모리 대역폭 병목 현상(Memory Bandwidth Bottleneck)을 해결하기 위해 설계되었다.
온칩 메모리(On-chip Memory) 활용: 압축된 가중치를 빠른 공유 메모리(Shared Memory)에서 해제하여 텐서 코어(Tensor Cores)에 직접 전달
4가지 실행 파이프라인(Execution Pipelines): 워크로드(Workload)에 따라 다양한 압축 해제 전략(Decompression Strategy) 선택
자동 튜닝(Autotuning): 각 가중치 행렬(Weight Matrix) 및 배치 크기(Batch Size)에 맞는 최적의 파이프라인을 선택하여 성능 극대화(Performance Maximization)
결과적으로 메모리 버스(Memory Bus)를 통과하는 데이터 양을 줄여 추론 속도를 향상시켰다.
4가지 실행 파이프라인의 작동 방식
Unweight는 워크로드(Workload)에 따라 유연하게 선택할 수 있는 4가지 실행 파이프라인을 제공한다.
Full Huffman Decode: 가장 단순한 방식으로, cuBLAS를 사용하여 표준 행렬 곱셈(Matrix Multiplication) 수행
Exponent-only Decode: 지수(Exponent) 값만 해제하여 메모리 트래픽(Memory Traffic) 절반 감소
Palette Transcode: 4비트 팔레트(Palette) 인덱스로 변환하여 전처리 비용(Preprocessing Cost) 최소화
Direct Palette: 전처리 없이, 행렬 곱셈 커널(Matrix Multiplication Kernel)에서 BF16 값 재구성
각 파이프라인은 압축 해제(Decompression)와 계산(Computation) 간의 트레이드 오프(Trade-off)를 가지며, 자동 튜닝을 통해 최적의 조합을 선택한다.
Unweight의 성능 및 한계
Unweight는 Llama-3.1-8B 모델에서 13%의 모델 크기 감소(Model Footprint Reduction)를 달성했으며, 배포 번들(Distribution Bundle)의 경우 최대 22%까지 압축 가능하다.
30~40%의 처리량 오버헤드(Throughput Overhead): 배치 크기(Batch Size) 1에서 41%, 1024에서 30%로 감소
Down Projection 압축 미적용: 전체 가중치의 약 1/3을 차지하는 다운 프로젝션(Down Projection) 압축 미적용으로 인한 성능 손실
커널 최적화(Kernel Optimization) 진행 중: 소규모 배치(Small Batch) 고정 비용, 중복된 가중치 재구성(Weight Reconstruction) 등 개선 여지 존재
향후 다운 프로젝션 압축 및 커널 최적화를 통해 성능을 더욱 향상시킬 계획이다.
Unweight의 생태계 확장성 및 미래 전망
Unweight는 모델 배포(Model Distribution) 및 추론(Inference) 환경 모두에서 활용될 수 있으며, Cloudflare의 인프라 비용 절감(Infrastructure Cost Reduction)에 기여한다.
모델 배포: Huffman 압축을 통해 모델 전송 시간 단축
추론 환경: 런타임(Runtime)에서 최적의 실행 경로 선택
Mixture-of-Experts 모델(Mixture-of-Experts Models) 지원: 콜드 익스퍼트(Cold Experts)를 온디맨드(On-demand)로 가져오는 환경에서 저장 공간 절약(Storage Space Saving) 효과 기대
향후 Unweight는 더 많은 LLM 모델에 적용될 것이며, 관련 연구를 통해 지속적인 발전을 이룰 것으로 예상된다.