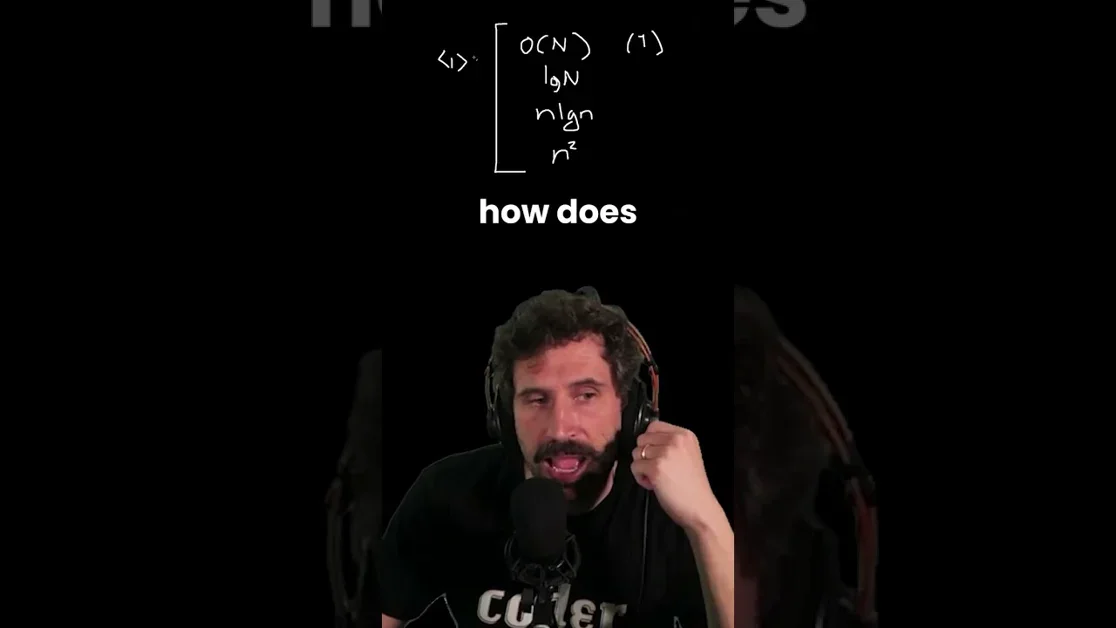O(1) 시간 복잡도, 가장 빠른 알고리즘!
by DD
2개월 전
조회수 16
알고리즘의 시간 복잡도 중 O(1) 상수 시간 개념을 설명하며, 입력 크기와 무관하게 일정한 실행 시간을 보장함을 강조함
O(1)은 가장 효율적인 시간 복잡도로, 데이터 구조 접근이나 간단한 연산에서 주로 나타남을 설명함
O(1)의 예시로 배열 인덱싱(Array Indexing)과 해시 테이블(Hash Table) 조회를 들며, 직접 접근(Direct Access)의 이점을 설명함
O(1) 상수 시간 복잡도의 정의
영상에서는 O(1)이 입력 데이터의 크기(n)에 관계없이 알고리즘 실행 시간이 일정함을 의미한다고 설명한다. 이는 가장 이상적인 시간 복잡도로 간주되며, 고정된 연산 횟수를 가진다고 요약된다. 즉, 입력이 아무리 커져도 처리 시간은 변하지 않는다는 점을 강조한다.
O(1)의 실제 적용 사례
발표자는 배열의 특정 인덱스 접근을 O(1)의 대표적인 예시로 들었다. 배열에서 `arr[5]`와 같이 특정 위치의 데이터에 접근하는 것은 배열의 크기와 상관없이 일정한 시간이 소요된다고 설명한다. 또한, 해시 테이블(Hash Table)에서의 키(Key)를 이용한 값 조회 역시 평균적으로 O(1)의 성능을 보인다고 언급한다.