동시성 성능 저하의 주범, 캐시 라인 공유!
동시성(Concurrency) 환경에서 발생하는 캐시 라인(Cache Line) 공유 문제로 인한 성능 저하를 설명함
데이터 정렬(Data Alignment) 및 청크 분할(Chunking) 등 다양한 해결 전략을 제시하며 성능 개선 효과를 분석함
실제 벤치마크를 통해 동시성 제어(Concurrency Control)의 중요성과 데이터 레이아웃(Data Layout) 최적화의 필요성을 강조함
오해하기 쉬운 병렬 처리의 함정: False Sharing
영상에서는 병렬 처리 시 각 스레드가 독립적으로 데이터를 처리하는 것처럼 보여도, 실제로는 CPU 캐시 라인(Cache Line) 공유로 인해 예상치 못한 성능 저하가 발생한다고 지적한다. 특히 여러 스레드가 동일한 캐시 라인 내의 다른 데이터를 수정할 때 발생하는 무효화(Invalidation) 과정이 성능 병목의 주범임을 강조한다. 이는 데이터 레이스(Data Race)와는 다른 개념으로, 동시 접근(Concurrent Access) 자체보다는 캐시 일관성 프로토콜(Cache Coherency Protocol)의 오버헤드에서 비롯된다.
간단한 모델링: False Sharing 발생 메커니즘 분석
발표자는 8바이트 메인 메모리와 각 코어당 4바이트 캐시 라인 2개를 가진 단순화된 모델을 제시한다. 여기서 핵심은 데이터 로딩 단위(Cache Line Granularity)인데, CPU는 요청된 데이터뿐만 아니라 연속된 데이터 블록(Contiguous Data Block)을 캐시 라인 단위로 로드한다. 따라서 서로 다른 스레드가 같은 캐시 라인에 속한 데이터를 수정하려 할 때, 캐시 무효화 신호(Cache Invalidation Signal)가 발생하며 다른 코어의 캐시를 무효화시켜 성능 저하를 유발함을 설명한다.
성능 개선 전략: 데이터 정렬과 청크 분할
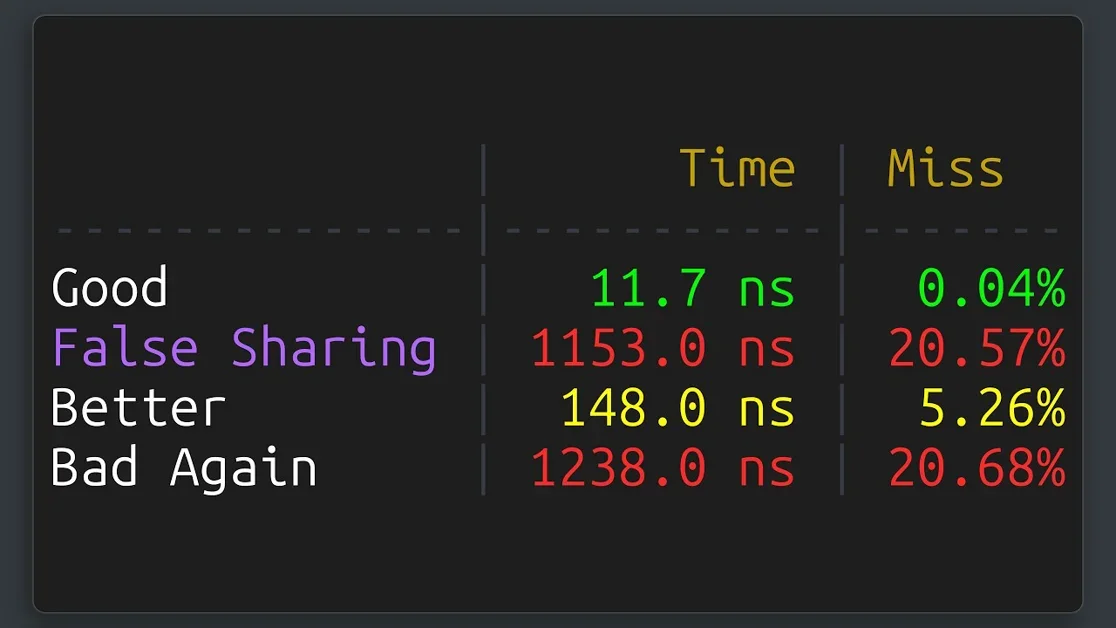
False Sharing 문제를 해결하기 위한 두 가지 주요 전략으로 데이터 정렬(Data Alignment)과 청크 분할(Chunking)을 제시한다. 데이터 정렬은 각 스레드가 사용하는 데이터를 별도의 캐시 라인(Separate Cache Lines)에 배치하여 충돌을 피하는 방식이다. 청크 분할은 각 스레드가 처리할 데이터 범위를 독립적인 메모리 영역(Independent Memory Regions)으로 나누어 할당함으로써, 동일 캐시 라인 접근 가능성을 낮추는 방법이다. 영상에서는 이 두 기법을 적용했을 때 성능이 수십 배 향상되는 벤치마크 결과를 보여준다.
실제 벤치마크: False Sharing의 영향력 검증
영상에서는 실제 벤치마크 도구를 사용하여 False Sharing의 영향을 정량적으로 측정한다. 초기에는 단일 스레드 성능이 높게 나오지만, 스레드 수가 증가함에 따라 성능이 급격히 하락하는 것을 보여준다. 특히, 데이터 레이아웃(Data Layout)이 최적화되지 않았을 경우, 스레드 수가 늘어날수록 성능 저하율이 기하급수적으로 증가함을 실험 결과로 입증한다. 이는 대규모 병렬 시스템(Large-scale Parallel Systems) 설계 시 데이터 구조 최적화(Data Structure Optimization)가 필수적임을 시사한다.
고급 기법: 스레드 로컬 스토리지와 캐시 라인 패딩
발표자는 더 나아가 스레드 로컬 스토리지(Thread-Local Storage, TLS)와 캐시 라인 패딩(Cache Line Padding) 같은 고급 기법을 언급한다. TLS는 각 스레드마다 고유한 데이터 복사본을 제공하여 데이터 격리(Data Isolation)를 강화한다. 캐시 라인 패딩은 데이터 구조 사이에 빈 공간(Padding)을 삽입하여 의도적으로 다른 캐시 라인에 배치하는 방식이다. 이러한 기법들은 데이터 구조 설계(Data Structure Design)의 미묘한 차이가 성능에 미치는 영향(Performance Impact)을 극명하게 보여준다.