GKE Spot VM에서 AI 워크로드 중단 없이 실행하기
by DD
1개월 전
조회수 6
Spot VM 활용 시 발생하는 예기치 못한 중단에 대비한 아키텍처 설계의 필요성 대두
SIGTERM 신호를 포착하여 정상 종료 절차(Graceful Shutdown)를 수행하는 방법 제시
체크포인트(Checkpoint) 외부 저장 및 멱등성(Idempotency) 보장으로 작업 재개 및 데이터 중복 방지
메시지 큐(Message Queue)를 활용한 워크로드 분리를 통해 작업 상태 관리 용이성 확보
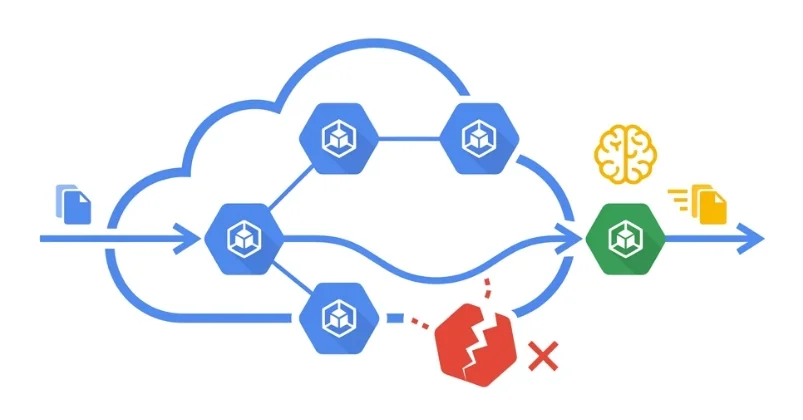
GKE Spot VM의 중단 메커니즘과 SIGTERM 처리
Google Cloud는 Spot VM을 회수하기 전, ACPI 신호를 통해 노드 종료 절차를 시작하며 Kubernetes는 이를 SIGTERM 신호로 변환하여 컨테이너에 전달함. 이 신호를 수신한 애플리케이션은 최대 15초의 유예 기간 내에 새로운 배치 처리를 중단하고, 현재 작업을 완료하며, 메모리 데이터를 디스크에 플러시한 후 성공 상태(exit code 0)로 종료해야 함. Python의 `signal` 모듈을 사용하여 이 SIGTERM 신호 핸들러를 구현할 수 있으며, 이는 정상 종료(Graceful Shutdown)를 위한 핵심 요소임.
체크포인트(Checkpoint)를 활용한 상태 복구 전략
Spot VM의 휘발성으로 인해 컨테이너가 종료되면 로컬 파일 시스템의 모든 데이터가 소실되므로, 모델 가중치, 옵티마이저 상태 등 진행 상황을 Google Cloud Storage(GCS)와 같은 외부 스토리지에 주기적으로 저장해야 함. GKE 클러스터와 동일 리전에 GCS 버킷을 구성하여 지연 시간(Latency)을 최소화하고 데이터 전송 비용을 절감하는 것이 중요함. 재시작 시에는 GCS 버킷에서 최신 체크포인트를 로드하여 중단된 시점부터 작업을 재개함으로써 손실된 작업(Lost Work)을 최소화할 수 있음.
멱등성(Idempotency)을 통한 데이터 중복 처리 방지
배치 추론 작업에서 동일한 데이터를 두 번 처리하여 데이터베이스에 중복 삽입되는 문제를 방지하기 위해 멱등성(Idempotency)을 보장하는 파이프라인 설계가 필수적임. 데이터베이스 작업 시 UPSERT (Update or Insert) 연산을 사용하거나, GPU 연산 전에 해당 작업이 이미 완료되었는지 확인하는 로직을 추가해야 함. 이를 통해 작업이 재시도되더라도 결과적으로 동일한 상태를 유지하며, 비용이 많이 드는 GPU 자원의 불필요한 사용을 방지할 수 있음.
Pub/Sub을 이용한 워크로드 큐 분리 및 관리
대규모 배치 처리 시, 단일 스크립트가 아닌 Pub/Sub과 같은 메시지 브로커를 활용하여 워크로드를 분리하는 것이 효과적임. 데이터셋을 개별 메시지로 분할하여 큐에 푸시하고, 워커 Pod는 메시지를 풀링하여 처리하며, 작업 완료 후 성공적으로 저장되었을 때만 Pub/Sub에 ACK(acknowledgment)를 보냄. 노드 중단 시 ACK가 전송되지 않은 메시지는 타임아웃 후 자동으로 재사용 가능해져, 데이터 유실 없이 원활하게 작업을 재개할 수 있음.
GKE Spot VM 활용을 위한 아키텍처 설계 원칙
Spot VM과 같은 비영구 컴퓨팅(Ephemeral Compute) 환경에서의 워크로드 실행은 단순한 인프라 선택을 넘어선 아키텍처 설계 결정임. 중단 신호 처리, 외부 스토리지로의 빈번한 체크포인트 저장, 멱등성 보장, 작업 큐 분리 등의 패턴을 적용함으로써 비용 절감 효과를 극대화하고 희소한 GPU 자원을 안정적으로 활용할 수 있음. 이는 AI 워크로드의 신뢰성(Reliability)을 유지하면서 비용 효율성(Cost-Effectiveness)을 높이는 핵심 전략임.