Redis CPU 100% 장애, Repository 대신 RedisTemplate으로 해결!
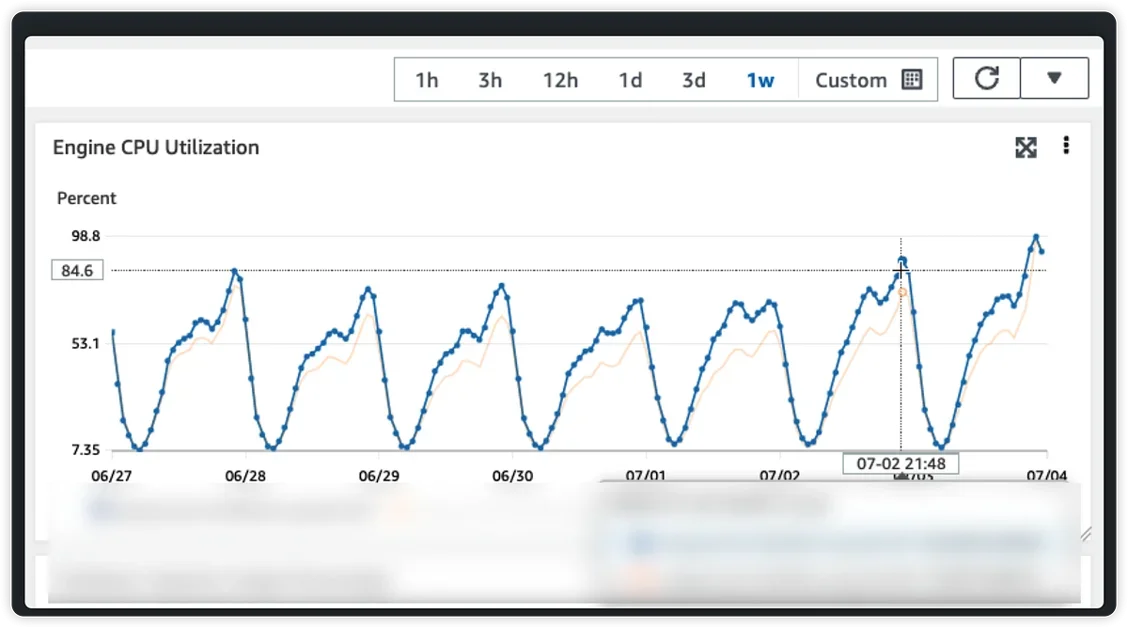
피크 타임마다 Redis CPU 100% 도달로 인한 서비스 응답 지연 및 타임아웃 문제 발생
Spring Data Redis Repository 사용 시 복잡한 객체 저장 시 다수의 Redis 명령어 실행 및 부가 메모리 사용으로 인한 부하 누적 확인
RedisTemplate으로 전환 후 CPU 사용률 10% 수준으로 감소, 응답 시간 정상 회복 및 서비스 안정성 확보
저장 작업에서 Repository 대비 RedisTemplate이 2.45배 빠름, 조회 작업은 1.35배 빠름 확인
캐싱 목적에는 RedisTemplate 또는 Spring Cache 사용 권장, 복잡한 쿼리 필요 시에만 Repository 사용 고려
Repository 방식의 부하 발생 원인 분석
Spring Data Redis Repository는 객체를 Hash 자료구조로 변환하여 저장하며, 보조 인덱스용 Set도 관리합니다. 데이터 규모 증가 및 사용자 증가로 인해 캐시 저장 요청 빈도가 상승하면, 한 번의 저장에 HMSET과 SADD 등 최소 2개 이상의 Redis 명령이 실행됩니다. 특히 복잡한 중첩 구조의 객체는 수백에서 수천 개의 필드를 포함하며, 이는 Redis 엔진이 처리해야 할 작업량을 폭증시켜 CPU 포화(CPU Saturation)의 근본 원인이 됩니다. 실제 프로덕션 환경에서는 초당 수백 건의 캐시 저장이 발생하며 CPU 사용률이 100%까지 치솟는 결과를 초래했습니다.
RedisTemplate 전환을 통한 성능 개선 효과
Repository 방식에서 RedisTemplate 방식으로 전환한 결과, Redis CPU 사용률이 100%에서 10% 수준으로 크게 감소했으며, 응답 시간 또한 정상 수준으로 회복되었습니다. JMH 벤치마크 테스트 결과, 저장 작업에서 Repository 대비 RedisTemplate이 2.45배 빠른 성능을 보였고, 조회 작업에서도 1.35배의 성능 향상을 확인했습니다. 복합 작업에서는 네트워크 왕복 시간(RTT)의 영향으로 차이가 줄었으나, 일관되게 RedisTemplate이 우수한 성능을 나타냈습니다. 이는 단일 SET 명령으로 데이터를 저장하는 RedisTemplate 방식이 다수의 Redis 명령과 추상화 레이어 오버헤드를 가진 Repository 방식보다 훨씬 효율적이기 때문입니다.
Repository의 부가 메모리 사용 및 구조
Spring Data Redis Repository는 Key-Value DB인 Redis의 한계를 극복하기 위해 보조 Set 및 인덱스를 추가로 활용합니다. 객체 저장 시 해당 객체의 키(ID)가 전체 키 목록 Set에 추가되며, `@Indexed` 필드를 사용하면 별도의 인덱스 Set이 생성됩니다. 예를 들어, `StayPdp` 객체 하나를 저장할 때 `StayPdp:88146` (Hash), `StayPdp` (Set), 그리고 `@Indexed` 필드에 따라 `StayPdp:placeName:조이` (Set)와 같은 추가 구조가 생성됩니다. 이로 인해 RedisTemplate 방식 대비 약 1.6배의 메모리 차이가 발생하며, 수십만 건의 데이터를 캐싱할 경우 수 GB의 메모리 낭비로 이어질 수 있습니다.
Repository vs RedisTemplate: 명령어 및 성능 비교
저장 작업 시 Repository는 `HMSET`과 `SADD` 등 최소 2개 이상의 명령어를 실행하는 반면, RedisTemplate은 단일 `SET` 명령으로 처리합니다. 조회 작업은 둘 다 단일 명령어를 사용하지만, Repository는 Hash 전체를 가져오는 `HGETALL`을 사용하는 반면 RedisTemplate은 단순 `GET`을 사용합니다. 삭제 작업 역시 Repository는 `DEL`, `SREM` 등 여러 명령어를 실행하지만 RedisTemplate은 `DEL` 하나로 충분합니다. 이러한 명령어 수와 처리 방식의 차이는 성능 및 CPU 효율성에서 명확한 차이를 발생시키며, 특히 저장 작업에서 Repository 방식의 성능 저하가 두드러집니다.
실무 적용 가이드: 언제 무엇을 사용해야 하는가?
일반적인 캐싱 목적(API 응답, DB 조회 결과, 외부 API 호출 결과 등)에는 Spring Data Redis Repository 대신 RedisTemplate 또는 Spring Cache (@Cacheable) 사용이 권장됩니다. Repository는 편리한 인터페이스를 제공하지만, 불필요한 오버헤드와 메모리 사용을 야기합니다. Repository는 Redis를 실제 데이터베이스로 사용하거나, 복잡한 쿼리 및 집계 기능이 필수적인 소규모 메타데이터/설정 관리, 임시 작업 큐 등에 제한적으로 사용하는 것이 좋습니다. 캐싱이 목적이라면 `@Cacheable`을 활용하고, 대량 데이터 캐싱이나 고성능이 요구되는 경우 RedisTemplate을 직접 사용하는 것이 효율적입니다.