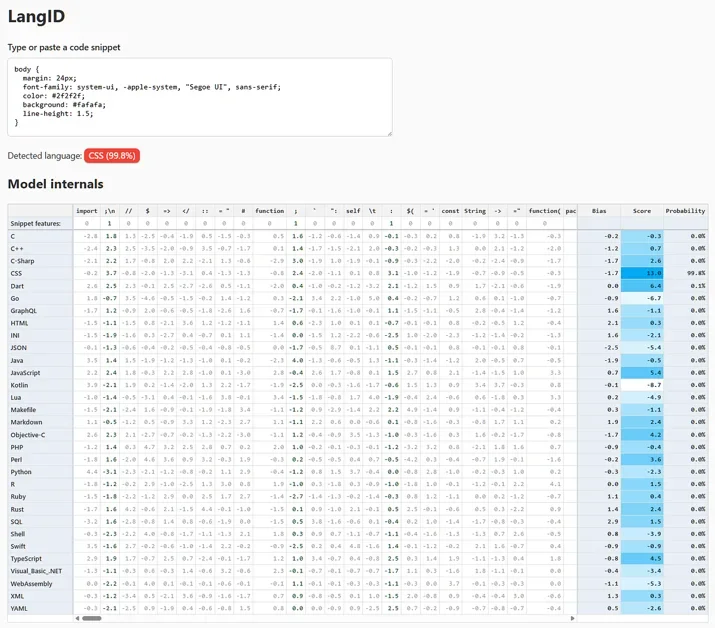
10KB 미만 초소형 언어 감지 모델 등장!
10KB 미만의 초소형 언어 감지 모델(Language Detection Model) 개발에 성공
모델 경량화를 위해 특정 기술(Specific Techniques)과 데이터셋(Dataset)을 활용
댓글에서는 기술적 세부 사항(Technical Details)에 대한 추가 정보 요청
모델 경량화 기법
게시물에서는 10KB 미만으로 언어 감지 모델 크기를 줄이기 위한 구체적인 기술적 접근 방식을 제시한다. 특히, 모델 압축(Model Compression), 양자화(Quantization), 지식 증류(Knowledge Distillation) 등의 기법을 활용하여 모델의 크기를 줄였을 것으로 예상된다. 이러한 기법들은 모델의 정확도(Accuracy)를 유지하면서도 계산량(Computational Cost)을 감소시키는 데 기여한다.
데이터셋 및 학습 과정
모델의 성능은 사용된 데이터셋(Dataset)의 품질에 크게 의존한다. 따라서, 다양한 언어의 텍스트 데이터를 수집하고, 데이터 전처리(Data Preprocessing) 과정을 거쳐 모델 학습에 적합한 형태로 변환했을 것이다. 또한, 과적합(Overfitting)을 방지하기 위해 정규화(Regularization) 기법을 사용하고, 검증 데이터셋(Validation Dataset)을 통해 모델의 일반화 성능을 평가했을 것으로 보인다.
커뮤니티의 관심사
댓글에서는 모델의 구체적인 구현 방식(Implementation Details)과 사용된 기술 스택(Tech Stack)에 대한 질문이 주를 이룬다. 특히, 모델의 정확도(Accuracy)와 속도(Speed)에 대한 정보, 그리고 모델의 배포(Deployment) 방법에 대한 관심이 높다. 또한, 오픈 소스(Open Source) 여부에 대한 질문도 제기되며, 모델의 재사용 가능성에 대한 기대감을 나타낸다.