Cron에서 분산 스케줄러로, 작업 처리량 극대화!
기존 Cron 작업 스케줄링(Cron Job Scheduling)의 한계를 극복하기 위한 분산 스케줄러(Distributed Scheduler) 도입 논의가 활발함
초당 수천 개(Thousands per Second)의 작업을 처리하기 위한 아키텍처 설계(Architecture Design) 및 기술 스택(Tech Stack)에 대한 관심 고조
데이터 격리 아키텍처(Data Isolation Architecture), 멱등성(Idempotency), 오케스트레이션(Orchestration) 등 분산 시스템(Distributed System) 관련 기술적 난제 논의
오픈소스(Open Source) 솔루션 및 상용(Commercial) 솔루션 비교를 통해 최적의 선택에 대한 고민 공유
Cron의 한계와 분산 스케줄러의 필요성
게시물에서는 기존 Cron 기반 시스템이 단일 서버(Single Server)에서 작업 관리를 수행하여 확장성(Scalability) 및 가용성(Availability)에 제약이 있다고 지적한다. 특히, 작업량이 증가함에 따라 Cron의 실행 시간(Execution Time) 예측이 어려워지고, 장애 발생 시 전체 시스템(Entire System)에 영향을 미칠 수 있다는 점을 강조한다. 따라서 분산 스케줄러(Distributed Scheduler)를 통해 이러한 문제점을 해결해야 한다는 주장이 제기된다.
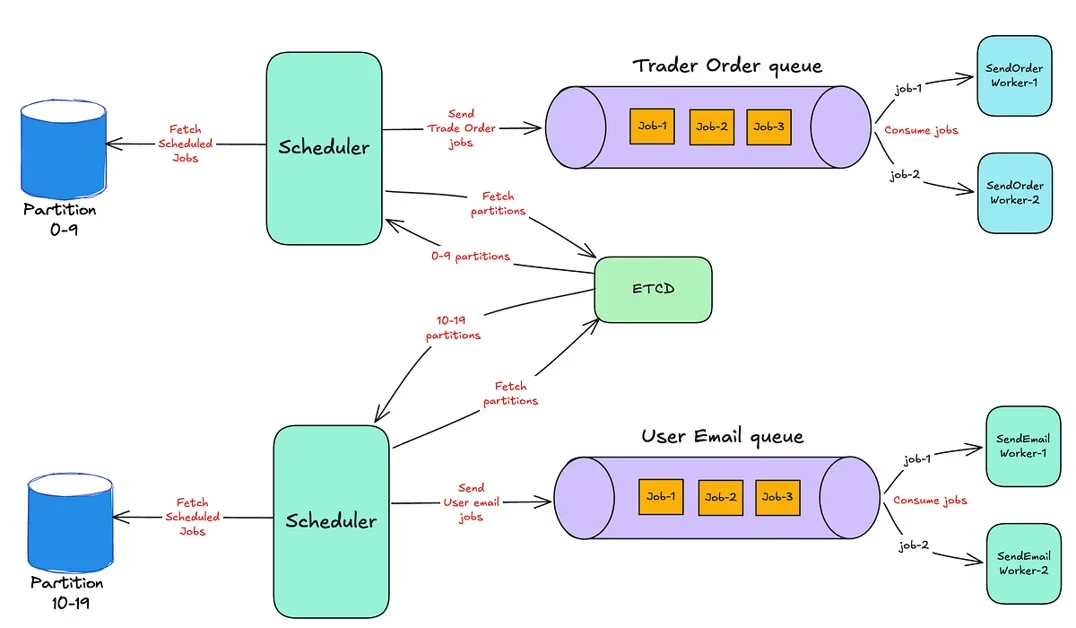
분산 스케줄러 아키텍처 설계
논의에서는 분산 스케줄러의 핵심 아키텍처 요소로 작업 큐(Job Queue), 작업 실행 엔진(Job Execution Engine), 스케줄링 알고리즘(Scheduling Algorithm)을 제시한다. 특히, 데이터 격리 아키텍처(Data Isolation Architecture)를 통해 작업 간의 간섭을 방지하고, 멱등성(Idempotency)을 확보하여 재시도(Retry) 시 데이터 일관성을 유지하는 것이 중요하다고 강조한다. 또한, 오케스트레이션(Orchestration) 도구를 활용하여 작업 실행 및 모니터링을 자동화하는 방안도 제시된다.
기술 스택 및 구현 고려 사항
커뮤니티에서는 Kafka, RabbitMQ와 같은 메시지 큐(Message Queue)를 활용하여 작업 큐를 구현하고, Kubernetes와 같은 컨테이너 오케스트레이션(Container Orchestration) 도구를 사용하여 작업 실행 환경을 구축하는 방안을 제시한다. 또한, 분산 트랜잭션(Distributed Transaction) 처리, 장애 복구(Fault Tolerance), 모니터링(Monitoring) 시스템 구축 등 분산 시스템(Distributed System)의 복잡성을 고려해야 한다고 강조한다. 구체적인 구현 코드는 본문에 포함되지 않았다.
오픈소스 vs 상용 솔루션 비교
댓글에서는 Airflow, Argo Workflows와 같은 오픈소스(Open Source) 분산 스케줄러와 AWS Step Functions, Google Cloud Scheduler와 같은 상용 솔루션의 장단점을 비교 분석한다. 오픈소스 솔루션은 유연성(Flexibility)과 커스터마이징(Customizing)의 장점이 있지만, 운영 및 유지보수(Maintenance)에 대한 부담이 존재한다. 반면, 상용 솔루션은 관리 편의성(Ease of Management)과 안정성(Stability)을 제공하지만, 비용(Cost) 및 종속성(Dependency) 문제가 발생할 수 있다.