수기 정산 자동화, 규칙과 검증 재설계를 통해 효율성 UP!
수기 정산의 비효율성을 개선하기 위해 정산 자동화를 시도했으나, 파일 기반 업무(File-based Task)의 한계에 직면함
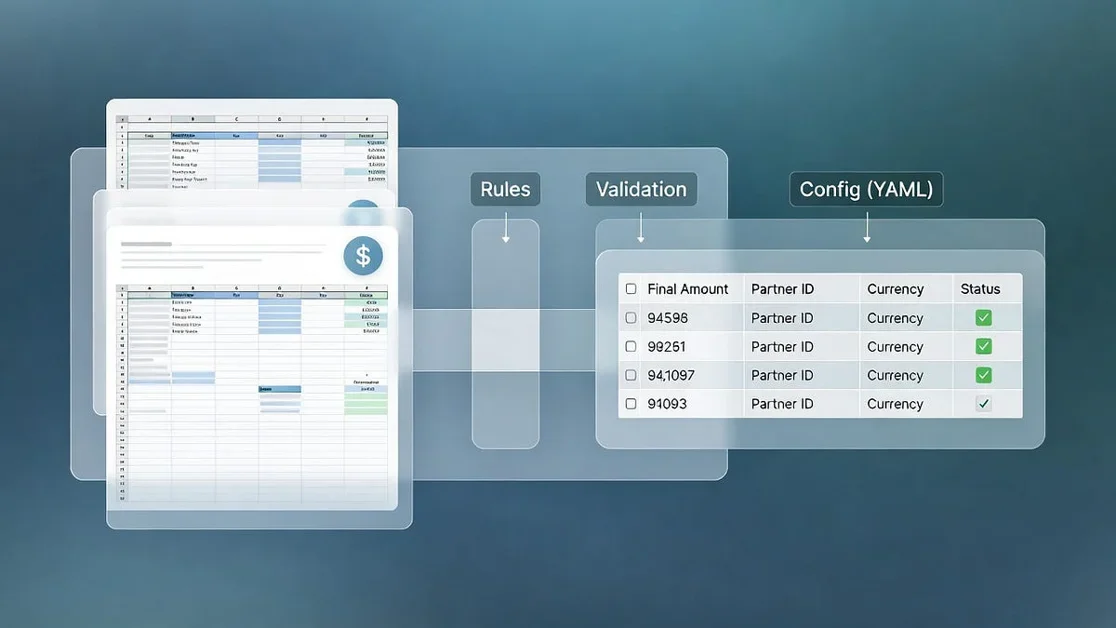
YAML 기반 규칙 관리(YAML-based Rule Management)를 도입하여 파트너별 상이한 정산 기준을 유연하게 처리하고, Config-driven ETL 방식을 채택함
검증 기능 강화(Enhanced Verification)를 통해 정산 결과의 추적 가능성을 확보하고, 데이터 무결성(Data Integrity)을 향상시킴
파일 기반으로 관리되던 소수의 별도 정산 업무를 내부 데이터 구조로 통합하여 데이터 관리 효율성(Data Management Efficiency)을 증대시킴
Config-driven ETL 아키텍처 설계
본 글에서는 파트너별 상이한 정산 규칙을 YAML 파일(YAML File)로 관리하고, 공통 실행 로직은 파이프라인으로 유지하는 Config-driven ETL 아키텍처(Config-driven ETL Architecture)를 소개한다.
규칙 분리(Rule Separation): 파트너별 정산 규칙을 코드에서 분리하여 유지보수성(Maintainability) 및 확장성(Scalability) 확보
설정 기반 관리(Configuration-based Management): 정산 규칙 변경 시 코드 수정 없이 설정 파일만 변경하여 배포 위험(Deployment Risk) 감소
데이터 검증(Data Validation): 정산 결과의 정합성(Consistency) 검증 및 근거를 함께 저장하여 데이터 신뢰도(Data Reliability) 향상
이러한 아키텍처는 데이터 파이프라인(Data Pipeline)의 유연성을 높이고, 다양한 데이터 소스(Data Source) 연동을 용이하게 한다.
Apps Script에서 YAML 기반 시스템으로의 전환
초기 구현에 사용된 Apps Script는 빠른 프로토타이핑(Rapid Prototyping)에 유리하지만, 파트너별 규칙 증가에 따라 유지보수성(Maintainability) 문제가 발생했다.
단일 스크립트(Single Script)의 한계: 모든 파트너의 규칙을 하나의 스크립트에서 관리하면서 코드 복잡도(Code Complexity) 증가
조건문 중첩(Nested Conditional Statements): 파트너별 상이한 정산 기준을 처리하기 위해 조건문이 과도하게 사용되어 코드 가독성(Code Readability) 저하
YAML 기반 규칙 관리(YAML-based Rule Management): 파트너별 규칙을 YAML 파일로 분리하여 코드 재사용성(Code Reusability) 및 관리 효율성(Management Efficiency) 향상
결과적으로, Apps Script는 초기 단계의 빠른 구현에 적합하며, 복잡한 시스템에서는 YAML과 같은 설정 기반 접근 방식이 더 효과적이다.
검증 기능 강화: 결과 추적 가능성 확보
본 글에서는 정산 결과의 추적 가능성(Traceability)을 확보하기 위해 검증 기능을 강화한 사례를 제시한다.
자동 검증(Automated Validation): 행 수, 금액 합계, 기준값 차이 등을 자동으로 확인하여 데이터 무결성(Data Integrity) 보장
근거 저장(Evidence Storage): 검증 결과를 설명할 수 있도록 근거를 함께 저장하여 감사(Audit) 및 문제 해결(Troubleshooting) 용이성 증대
내부 DB 연동(Internal DB Integration): 정산 결과를 내부 DB에 저장하여 데이터 접근성(Data Accessibility) 및 분석(Analysis) 용이성 향상
이러한 검증 기능 강화는 데이터 기반 의사 결정(Data-driven Decision Making)을 지원하고, 데이터 관리의 신뢰성을 높이는 데 기여한다.
별도 정산 업무의 내부 데이터 구조 내재화
본 글에서는 파일 기반으로 관리되던 소수의 별도 정산 업무를 내부 데이터 구조로 통합하여 데이터 관리 효율성(Data Management Efficiency)을 높인 사례를 소개한다.
데이터 통합(Data Integration): 별도 정산 데이터를 기존 내부 DB 구조에 통합하여 데이터 중복(Data Redundancy) 제거 및 일관성(Consistency) 유지
단일 데이터 뷰(Single Data View): 모든 정산 데이터를 동일한 방식으로 관리하여 데이터 분석(Data Analysis) 및 보고(Reporting) 용이성 증대
자동화 범위 확장(Automation Scope Expansion): 별도 정산 업무 자동화를 통해 업무 생산성(Productivity) 향상 및 인적 오류(Human Error) 감소
결과적으로, 데이터 구조 내재화는 데이터 관리의 효율성을 높이고, 데이터 기반 의사 결정을 지원하는 데 기여한다.