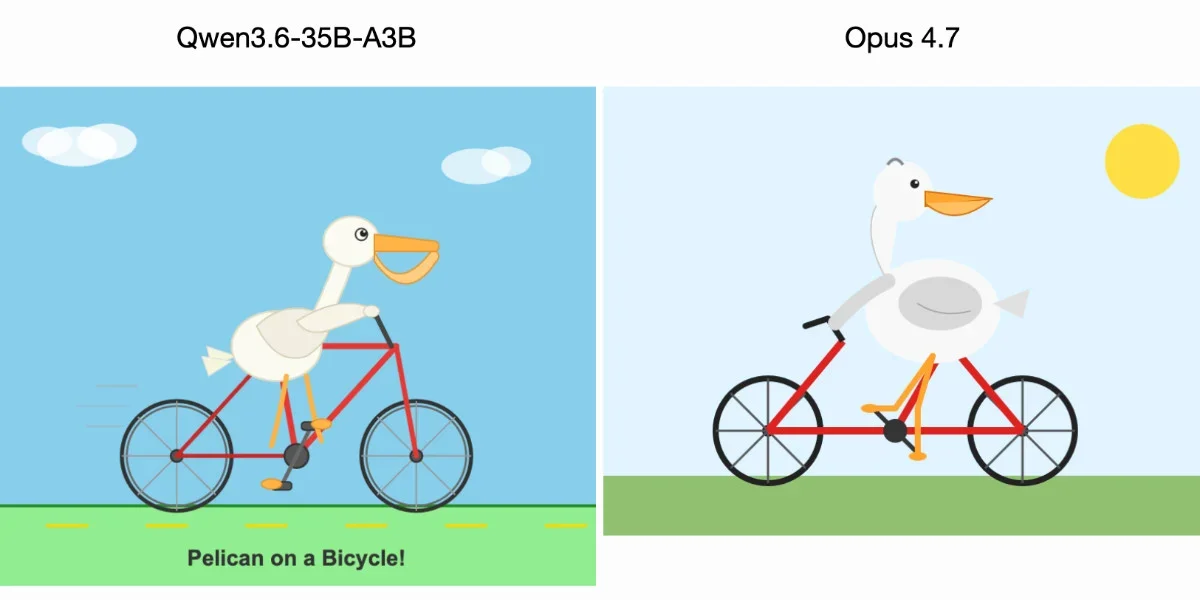
Qwen3.6, 펠리컨 그림 대결에서 Claude Opus 4.7을 넘어서다!
by DD
3개월 전
조회수 38
Qwen3.6-35B-A3B 모델이 펠리컨 그림 생성 벤치마크에서 Claude Opus 4.7보다 우수한 결과를 보이며 모델 성능 논쟁(Model Performance Debate)에 불을 지핌
SVG 생성 능력(SVG Generation)은 LLM의 훈련 데이터에 의존적이며, 특정 작업에 대한 최적화가 이루어지고 있다는 지적
벤치마크의 유효성(Benchmark Validity)에 대한 의문 제기, 펠리컨 벤치마크가 모델 성능을 정확하게 반영하는지에 대한 논쟁
실용성 부족(Lack of Practicality)에 대한 비판, 그림 생성 능력 향상이 실제 사용 사례에 미치는 영향에 대한 의문
펠리컨 벤치마크의 한계와 모델 훈련의 변화
커뮤니티에서는 펠리컨 그림 벤치마크가 모델의 일반적인 성능을 대표하지 못한다는 비판이 제기되었다. SVG 생성(SVG Generation)과 같은 특정 작업에 대한 모델의 훈련은 PR 목적이나 특정 벤치마크를 위한 과도한 최적화로 이어질 수 있다는 지적이다. 특히, 모델 크기가 커지는 추세가 둔화되면서, 특정 작업에 대한 미세 조정(Fine-tuning)이 성능 향상의 주요 원동력이 되고 있다.
Qwen3.6-35B-A3B의 성능 분석
Qwen3.6-35B-A3B 모델은 펠리컨 그림 생성에서 Claude Opus 4.7보다 우수한 결과를 보였지만, 코딩 관련 작업에서는 3.5 버전에 비해 미미한 개선을 보였다는 평가가 있다. Power Ranking 테스트에서 3.6 버전은 11/98 문제를 해결한 반면, 3.5 버전은 26/98 문제를 해결했다. 이는 펠리컨 그림 생성에서의 우위가 모델의 전반적인 성능 향상을 의미하지 않음을 시사한다.
실제 사용 사례에서의 LLM 성능
일부 사용자는 LLM이 실제 사용 사례에서 겪는 어려움을 지적했다. 예를 들어, Gemini 모델이 슬라이드 다이어그램을 업데이트하는 데 실패하는 사례를 언급하며, 단순한 변경 요청(Simple Change Request)에도 제대로 응답하지 못하는 문제를 지적했다. 이는 벤치마크 결과와 실제 사용 간의 괴리(Gap)를 보여주는 사례로, 모델의 실용성에 대한 의문을 제기한다.
모델 비교의 어려움과 벤치마크의 의미
모델 간의 성능 비교는 벤치마크의 목적과 한계에 대한 논의를 촉발했다. 펠리컨 벤치마크는 재미를 위한 것이었지만, 모델 훈련 과정에서 벤치마크에 대한 과도한 최적화(Overfitting)가 이루어질 수 있다는 비판이 제기되었다. 또한, 벤치마크 결과가 모델의 일반적인 유용성을 정확하게 반영하는지에 대한 의문이 제기되며, 다양한 테스트 환경(Diverse Testing Environment)의 필요성이 강조된다.